Закономерные награды и наказания
Закономерные награды и наказания
Изучение окружающего мира без помощи учителя
Наш мозг постоянно изучает окружающий мир. Ему постоянно приходится распознавать встречающиеся предметы, чтобы понять, стоит ли приближаться к ним или избегать их. Ему нужно учиться срывать плоды и не хватать рукой осу, чтобы она нас не ужалила. Более того, это обучение происходит без помощи учителя. Рядом с нами нет никого, кто мог бы всегда подсказать нам, правильно или нетто, что мы делаем.
Один из плюсов научной работы – возможность путешествовать. Каждый месяц где-нибудь проходит конференция, в которой я могу участвовать, и нередко мне готовы оплатить все расходы. И вот я иду по еще одному городу, в котором я никогда раньше не бывал, и ищу конференц-центр, где мне предстоит встретиться со многими людьми, которых я никогда раньше не видел, и где я буду искать среди них тех, кого я уже знаю, чтобы поговорить с ними. Но кто это там? Неужели это мой оппонент, профессор английского языка? А я-то думал, что это естественно-научная конференция.
Я никогда раньше не видел этого города, и все же мне несложно было ходить по нему. Мне нравится приезжать в новые места и одному бродить по улицам. При этом я узнаю для себя много нового, но мне не требуется постоянное руководство учителя. В детстве большая часть обучения тоже проходит без учителя. Никто не научит вас кататься на велосипеде. Чтобы этому научиться, нужно самому это делать. Мы выучиваем основы языка до того, как нас начинают учить. Девятимесячный младенец-американец может научиться отличать разные звуки китайского языка, просто находясь в одной комнате с человеком, говорящим по-китайски.
Как же происходит это обучение без учителя?
Изучение будущего
Ученые завоевывают место в массовой культуре оттого, что люди находят в них самих или в их работе что-нибудь необычное или экстравагантное. Мы знаем, что Галилей бросал что-то с наклонной Пизанской башни, хотя мы толком и не знаем зачем. Мы уверены, что Эйнштейн сделал какие-то очень важные открытия, касающиеся пространства и времени, хотя всё, что мы на самом деле знаем о нем, это что у него была забавная прическа.
Иван Петрович Павлов – еще один такой ученый. Несмотря на то что он проводил свои эксперименты уже лет сто назад, все знают, что он добивался, чтобы у собаки выделялась слюна в ответ на звон колокольчика. Это кажется нам экстравагантным по ряду причин. Почему он изучал собак, а не крыс, как большинство ученых?[91] Почему отмечал выделение слюны, хотя намного проще было бы наблюдать какие-нибудь очевидные движения? Почему, чтобы подавать сигнал, он выбрал именно колокольчик? И главное, зачем он вообще все это делал?

Рис. 4.1. Иван Петрович Павлов (1849-1936).
Фотография Павлова (в центре) с одной из его собак в ходе демонстрации. Павлов открыл классические условные рефлексы – самую базовую форму ассоциативного обучения.
Исследования Павлова важны потому, что позволили открыть некоторые фундаментальные особенности обучения, свойственные в равной степени и животным, и людям. Открытые Павловым закономерности относятся не только к собакам, выделению слюны и звону колокольчика.[92] Павлов изучал выделение слюны, потому что первоначально предметом его интереса было пищеварение. У всех нас, как и у собак, слюна начинает выделяться автоматически примерно через одну секунду после того, как пища оказывается во рту. Это самый первый этап процесса переваривания пищи. Здесь нет ничего удивительного. Между пищей и пищеварением есть прямая связь. Пища ценна для нас именно тем, что мы можем ее переварить. Павлов назвал процесс выделения слюны в ответ на оказавшуюся во рту пищу безусловным рефлексом.
Но Павлов также открыл, возможно случайно, что любой сигнал, подаваемый в момент приема пищи, например звук тикающего метронома, будет сам по себе вызывать слюноотделение. Если звук метронома раздавался непосредственно перед тем, как у собаки во рту оказывалась еда, то после четырех- или пятикратного повторения этой процедуры звук метронома будет вызывать слюноотделение и без всякой пищи. Павлов назвал это условным рефлексом. Он предположил, что звук метронома превратился в сигнал приема пищи. У собаки не просто выделялась слюна при звуке метронома. Она также поворачивалась туда, где ей обычно давали еду, и начинала активно облизываться. Услышав звук, собака ожидала появления пищи.[93]
Звук тикающего метронома "не имеет никакого отношения" к пище, и совершенно неважно, какой именно раздражитель использовать. Павлов испробовал множество разных раздражителей. Запах ванили, звук электрического звонка, вид вращающегося предмета – все эти раздражители могли служить сигналами появления пищи.
Пока мы голодны, мы хотим получить пищу. Пища служит нам наградой. Нас влечет к ней. На вечеринках мы готовы проталкиваться сквозь толпу, неизбежно возникающую у стола с едой, игнорируя все попытки завязать разговор, пока не наберем себе полную тарелку. Павлов показал, что любой раздражитель может стать сигналом появления еды и заставить животных стремиться к этому раздражителю. Вот почему люди на вечеринке машинально стремятся в ту часть комнаты, где толпится особенно много народу. Мы научены, что именно там можно найти еду и напитки.
Кроме того, Павлов показал, что точно такое же обучение происходит и если использовать наказание вместо награды. Если положить собаке в рот что-нибудь неприятное на вкус, она попытается избавиться от этого, тряся головой, открыв рот и работая языком (а также выделяя слюну). Любой раздражитель, например то же тиканье метронома, тоже может служить сигналом подобного наказания, которого мы, как и собаки, будем стремиться избежать.
Павлов нашел экспериментальный метод, позволяющий исследовать самые базовые формы обучения. Такое обучение называют ассоциативным, потому что при этом возникает ассоциация между посторонним раздражителем и наградой (например, пищей) или наказанием (например, электрическим ударом). Такое обучение играет важную роль в приобретении знаний об окружающем мире. Этот механизм позволяет нам выучить, какие вещи нам приятны, а какие неприятны. Например, цвет может служить сигналом того, что плод созрел. При созревании плоды обычно краснеют или, точнее, становятся менее зелеными, из-за разложения хлорофилла. Мы предпочитаем приятные зрелые плоды неприятным незрелым. И мы можем научиться отличать приятные плоды от неприятных по цвету.
Но слово "ассоциация" можно понять неправильно. Для обучения недостаточно, чтобы звук колокольчика раздавался примерно в то же время, когда собаке дают пищу. Павлов отмечает, что в одном из экспериментов никакого обучения не наблюдалось после того, как 374 раза прозвучал громкий звонок в сочетании с поступлением пищи. Так получалось оттого, что звонок всякий раз раздавался лишь через 5-10 секунд после того, как пища оказывалась у собаки во рту. Посторонний раздражитель интересен лишь в том случае, если он позволяет предсказывать, что в будущем произойдет что-либо приятное или неприятное. Если этот раздражитель вступает в действие уже после какого-либо важного события, никакого интереса он не представляет. В этом случае мы уже знаем, что важное событие произошло. Такой сигнал не сообщает нам ничего нового, поэтому мы не обращаем на него внимания.
Открытая Павловым форма обучения совершенно необходима нам для выживания. Такое обучение позволяет распознавать в окружающем мире все те полезные раздражители, по которым можно узнать, что произойдет в будущем. Но хотя научиться тому, какие вещи окажутся приятными, а какие сулят неприятности, очень полезно, для выживания этого недостаточно. Нам необходимо также научиться, что делать, чтобы получать приятные вещи, и что делать, чтобы избегать неприятностей.
Примерно в то же время, когда Павлов в Санкт-Петербурге вызывал слюноотделение у собак, Эдвард Торндайк в Нью-Йорке помещал кошек в специально сконструированные клетки-головоломки. Это были небольшие клетки с дверцей, которую кошка могла открыть определенным способом, например дернув за веревочную петлю. Торндайк показал, что кошки могут научиться дергать за веревочку, выбираться из клетки и добираться до рыбы, положенной перед клеткой. Но главный вопрос, на который он хотел ответить, состоял в том, как кошки этому обучаются. Торндайк понял, что для ответа на этот вопрос нужно узнать, как они не обучаются. Он показал, что кошкам не помогало наличие учителя.[94] Кошки не обучались путем имитации. Неоднократное наблюдение за кошкой, которая уже научилась выбираться из клетки, потянув за веревочку, ничуть не помогало другой кошке. Торндайк также продемонстрировал, что кошки не учатся путем демонстраций. Он брал кошачью лапу в руку и тянул ею за веревочку, тем самым выпуская кошку из клетки наружу, где она могла съесть рыбу. Но и после многих таких демонстраций кошка, которую оставляли в клетке в покое, далеко не сразу тянула за веревочку.

Рис. 4.2. Одна из клеток-головоломок Эдварда Торндайка.
Торндайк открыл инструментальное обучение – еще одну базовую форму ассоциативного обучения. Кошка может научиться выбираться из клетки и добираться до рыбы, положенной возле самой клетки.
Торндайк пришел к выводу, что кошки могут научиться выбираться из клетки исключительно методом проб и ошибок. Как только кошку сажали в клетку, она сразу начинала пытаться выбраться наружу и добраться до рыбы. Кошка пыталась протиснуться в любую щель, дергала прутья когтями и кусала их, просовывала в щели лапы и хватала когтями все, до чего могла дотянуться. Рано или поздно она случайно цеплялась когтями за веревочную петлю, дергала ее, и дверца открывалась. Каждый следующий раз посаженная в клетку кошка выбиралась наружу немного быстрее. Ей требовалось все меньше времени, чтобы потянуть за веревочку, пока наконец она не начинала тянуть за веревочку сразу, как только ее сажали в клетку.
Торндайк также понял, что это было тоже ассоциативное обучение. Кошка училась ассоциировать действие (дерганье за веревочку) с наградой (возможностью выбраться из клетки и съесть рыбу). Всем животным свойственна эта форма обучения. Мы, люди, тоже, как кошки, с большей вероятностью выполняем действия, за которыми следует что-то приятное. Обратное тоже верно, как и в случае с обучением, которое исследовал Павлов. Мы с меньшей вероятностью выполняем какие-либо действия, за которыми следует что-то неприятное. Мы также можем разучиться действовать в соответствии с некоторой ассоциацией (это происходит, например, при так называемом торможении условного рефлекса). Если дверца перестанет открываться в ответ на дерганье за веревочку, кошка рано или поздно перестанет за нее дергать.
Этот механизм обучения позволяет нам выяснять, какие наши действия скажутся на будущем.
Обучение суевериям
Если кошка научилась выбираться из клетки, дергая за веревочку, это еще не значит, что она разобралась в том, каким образом веревочка открывает дверцу. Она с тем же успехом научилась бы этому, если бы требуемое действие "не имело никакого отношения" к награде, как в случае с обучением, которое исследовал Павлов. Любое действие, которое происходит непосредственно перед получением награды, будет повторено с повышенной вероятностью.
Впоследствии ученый следующего поколения после Торндайка, Беррес Фредерик Скиннер[95], сконструировал названный его именем проблемный ящик, который, по сути, представляет собой усовершенствованный и автоматизированный вариант клетки-головоломки Торндайка. Находящееся в ящике животное нажимает лапкой на рычажок (если это крыса) или клювом на кнопку (если это голубь) и автоматически получает награду или наказание. При этом ведется постоянная запись хронологии всех подобных событий.
Этот ящик позволил Скиннеру продемонстрировать произвольный характер выработки поведенческих реакций в изящнейшем эксперименте с "суеверностью" голубей. Голодного голубя сажали в ящик Скиннера и подавали ему еду через одинаковые промежутки времени, вообще никак не связанные с его поведением. Через некоторое время можно было наблюдать неоднократное выполнение голубем того или иного случайно выбранного действия. Один голубь поворачивался в ящике против часовой стрелки, совершая два или три таких поворота перед появлением еды. Другой голубь раз за разом тыкался клювом в один из верхних углов ящика. У третьего выработалась реакция "подбрасывания": он как бы просовывал голову под невидимую планку и несколько раз подкидывал ее вверх. Голуби научились повторять любые действия, которые они по чистой случайности совершали перед самым появлением пищи. Скиннер назвал такое поведение "суеверным", поскольку голуби вели себя так, как будто верили, что их поведение вызывает появление пищи, хотя в действительности это было не так. Он предположил, что суеверное поведение людей может возникать точно таким же образом.
Возможно, именно этим объясняется, что многие спортсмены и их болельщики имеют особые талисманы и большое значение придают ритуальным действиям, выполняемым перед игрой. Некоторые теннисисты всегда определенным образом отбивают мячик от земли, прежде чем сделать подачу. Утверждают, что Горан Иванишевич старался не касаться своей головы или бороды и усов на протяжении всего турнира.
Студенты-психологи быстро взяли эти данные о суеверном поведении на вооружение. У меня есть сведения из надежного источника, что студенты Кембриджа 1968 года выпуска успешно заставили одного выдающегося нейрофизиолога читать лекцию, стоя у левого края подиума, тем, что начинали зевать и ронять карандаши всякий раз, когда он отходил вправо. Интересная особенность подобных экспериментов состоит в том, что они удаются лишь в тех случаях, когда испытуемый не знает, что обучается условиям получения награды или наказания. Для обучения ассоциациям совсем не обязательно понимать, чему обучаешься. Напротив, не понимать, чему обучаешься, даже лучше.
В первой части этой книги показано, как много наш мозг знает об окружающем мире такого, что вообще не достигает нашего сознания. Это в особенности относится к знаниям, получаемым в ходе ассоциативного обучения. Именно поэтому нам кажется, что мы воспринимаем окружающее и действуем с такой легкостью. Мы не осознаём, как много сведений накоплено нашим мозгом, чтобы помочь нам взаимодействовать с окружающим миром. Когда вы прочтете ниже, что мы учимся предсказывать будущее, не забывайте, что обычно мы делаем это неосознанно и непреднамеренно.
Как наш мозг учится?
Обе разновидности ассоциативного обучения связаны с будущим. Мы выучиваем определенные сигналы, которые говорят нам о том, что случится в будущем. Мы выучиваем определенные действия, которые влияют на то, что случится в будущем. При этом, разумеется, будущее предсказывают не сами сигналы. Предсказания делает наш мозг. Мы можем увидеть, как он это делает, непосредственно исследуя активность нервных клеток.[96]
Нервные клетки, в сущности, представляют собой сигнальные устройства. Информация передается из одного конца клетки в другой посредством электричества, примерно так же, как по телефонному проводу (см. главу 5).[97] Но что происходит, когда сигнал достигает конца клетки? Похожая проблема есть и с телефоном. Между ухом и телефоном нет электрической связи. Их разделяет промежуток. В случае с телефоном эта проблема решается посредством молекул воздуха, с помощью которых передается сигнал. В трубке есть устройство, которое заставляет молекулы воздуха колебаться, эти колебания преодолевают разделяющий трубку и ухо промежуток, и ухо улавливает их. В случае с нервными клетками механизм, обеспечивающий передачу сигнала через промежуток, разделяющий клетки, намного сложнее. В упрощенном виде он выглядит следующим образом. Когда электрический сигнал достигает конца клетки, в щель между клетками выделяется определенное вещество, которое возбуждает следующую клетку. Такой промежуток между клетками называется синапсом (или, точнее, синаптической щелью). Вещества, которые переносят сигнал через синаптические щели, называют нейромедиаторами. В мозгу было обнаружено много разных нейромедиаторов. Нервные клетки можно разделить на типы в соответствии с используемым нейромедиатором.
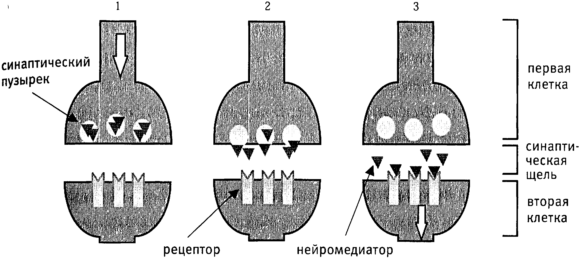
Рис. 4.3. Синапс.
Место передачи сигнала от одной нервной клетки к другой.
1. Нервный импульс (потенциал действия) достигает пресинаптической мембраны на конце одной клетки.
2. Из-за этого пузырьки подплывают к мембране и выделяют содержащийся в них нейромедиатор в синаптическую щель.
3. Молекулы нейромедиатора достигают рецепторов, расположенных на постсинаптической мембране, принадлежащей второй клетке. Если это возбуждающий синапс и сигнал окажется достаточно сильным, это может запустить нервный импульс во второй клетке. Если это тормозной синапс, то постсинаптическая клетка станет менее активной. Однако каждый нейрон обычно связан синапсами со многими другими, поэтому что произойдет во второй клетке, зависит от суммарного эффекта воздействия всех ее синапсов. Впоследствии нейротрансмиттеры снова поглощаются пресинаптической мембраной, и весь цикл может повториться снова.
К одному из таких типов относятся очень важные клетки выделяющие нейромедиатор допамин. Эти клетки часто называют клетками награды (reward cells), потому что их активность увеличивается после того, как животное получает пищу или питье. Крыса будет охотно нажимать на рычажок, вызывающий стимуляцию этих клеток, и предпочтет эту стимуляцию даже еде или сексу. Это так называемая самостимуляция.[98]
Вольфрам Шульц отслеживал активность этих клеток в эксперименте на формирование условного рефлекса и обнаружил, что на самом деле это не клетки награды. В этом эксперименте через одну секунду после постороннего, как и в опытах Павлова, сигнала (световой вспышки) обезьяне в рот впрыскивали порцию фруктового сока. Вначале допаминовые нервные клетки играли роль клеток награды, реагируя на поступление сока, но по окончании обучения они перестали активироваться в момент вспрыскивания сока. Вместо этого они теперь активировались сразу после того, как обезьяна видела вспышку, за секунду до поступления сока. Судя по всему, возбуждение допаминовых клеток служило сигналом того, что скоро должен быть получен сок. Они не реагировали на награду, а предсказывали ее получение.
Связь работы этих клеток с предсказанием проявлялась еще нагляднее, когда обезьяна видела вспышку, но сока после этого не получала. В тот момент, когда должен был поступить сок, активность допаминовых нервных клеток снижалась. Мозг обезьяны предсказывал, когда именно можно ожидать награды в виде сока, и снижение активности допаминовых клеток сигнализировало, что награда не получена.
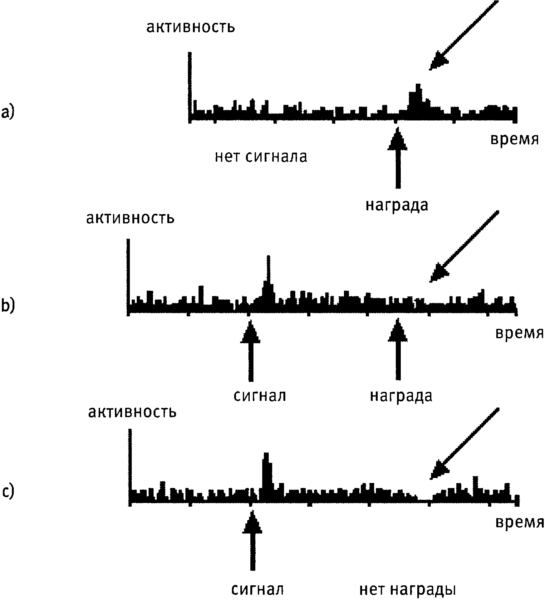
Рис. 4.4. Активность допаминовых нейронов отражает ошибку в предсказании награды.
Обезьян обучали ассоциировать световую вспышку (сигнал) с фруктовым соком, вспрыскиваемым в рот через секунду (награда), измеряя при этом активность допаминовых нейронов.
(a) Сигнала не поступало, и обезьяна не знала, когда получит награду. Непредвиденная награда вызывает повышение активности.
(b) Обезьяна знала, когда получит награду. Получение награды не вызывает изменений активности. Но обезьяна не знала, когда поступит сигнал. Непредвиденный сигнал, предвещающий награду, вызывает повышение активности.
(c) Обезьяна ожидала получения награды, но не получила ее. Отсутствие предвиденной награды вызывает снижение активности.
Как мы учимся на своих ошибках
Активность этих клеток не служит сигналом награды. Не служит она и сигналом того, что награда скоро будет получена. Активность этих клеток сообщает нам об ошибке в нашем предсказании награды. Если сок поступает тогда, когда мы ожидаем его поступления, значит, никакой ошибки в нашем предсказании нет, и допаминовые клетки не посылают сигнала. Если сок поступает неожиданно, значит, награда превзошла наши ожидания, и эти клетки посылают положительный сигнал. Если же сок не поступает, когда мы его ожидаем, значит, награда не оправдала наших ожиданий, и допаминовые клетки посылают отрицательный сигнал. Эти сигналы, сообщающие нам об ошибках в наших собственных предсказаниях, позволяют нам изучать окружающий мир, не нуждаясь в учителе. Если наши предсказания о чем-то в окружающем мире ошибочны, это означает, что нам нужно что-то сделать, чтобы улучшить качество своих предсказаний.
Еще до того, как выяснилось, что активность допаминовых нервных клеток служит сигналом ошибки в наших предсказаниях, математики разработали алгоритмы, позволяющие машинам обучаться похожим способом.
Для понимания механизмов подобного ассоциативного обучения важна концепция "ценности". Безусловный раздражитель в экспериментах Павлова обладает внутренней ценностью – положительной в случае еды (награда) и отрицательной в случае электрического удара (наказание). Этот ассоциативный механизм работает благодаря тому, что всякий раз, когда мы получаем награду, что угодно, предшествовавшее этой награде, приобретает дополнительную ценность. Даже нечто случившееся задолго до награды становится хотя бы чуть-чуть более ценным. Некоторые из таких вещей никак не связаны с наградой и предшествовали ей по чистой случайности. Но тогда, вероятнее всего, когда что-то подобное произойдет в следующий раз, за ним не последует награды. Это вызовет поступление сигнала об ошибке. Ожидаемая награда не была получена, и ценность не связанного с ней события будет снижена. Но когда происходит нечто, позволяющее правильно предсказать получение награды, сигнал об ошибке не поступает, и такое событие приобретает с каждым разом все большую ценность. Тем самым наш мозг учится присваивать определенную ценность всем событиям, объектам и местам в окружающем нас мире. Многие из них при этом остаются для нас безразличными, но многие приобретают высокую или низкую ценность.
Мы испытываем ощущения, отражающие эту карту ценностей, заключенную в нашем мозгу, когда возвращаемся из долгой заграничной поездки: мы чувствуем прилив эмоций, нарастающий по мере того, как улицы, по которым мы движемся, становятся все более знакомыми.
Стремясь к тому, что обладает высокой ценностью, и избегая того, что обладает низкой ценностью, мы можем получать награды и избегать наказаний. Но этот механизм ассоциативного обучения говорит нам только о том, какие вещи обладают высокой ценностью. Он не говорит нам, как добиться этих ценных вещей. Кошки Торндайка, когда их впервые сажали в клетку-головоломку, знали, что рыба обладает высокой ценностью, но при этом не знали, что сделать, чтобы до нее добраться.
Механизм, позволяющий научиться, что делать, чтобы получать награды (или избегать наказаний), тоже существует. Его называют алгоритмом временных различий. Используя этот метод, машина может определить наилучшую последовательность действий, которые требуется совершить, чтобы получить что-либо ценное. Этот метод известен также как "модель актера и критика". Одна часть программы, "актер", решает, какое следующее действие предпринять. Другая часть, "критик", оценивает, насколько удачным было это действие. Критик сообщает актеру обо всех ошибках, допущенных в предсказаниях. Удачным действием считается такое, после которого наше положение сейчас оказывается лучше, чем было до того. Критик всякий раз сообщает о происходящих изменениях ценности (отсюда "временные различия"). Ценность положения повышается после действий, которые приближают нас к награде. Это позволяет нам искать пути, ведущие к получению награды. Самой высокой ценностью обладает место возле самой награды. По мере удаления от награды ценность уменьшается. Двигаясь в сторону мест с более высокой ценностью, мы рано или поздно доберемся до награды. При этом, разумеется, в окружающем мире нет никаких отметок, указывающих ценность того или иного места. Эти отметки существуют лишь во внутренней модели мира, имеющейся у нас в мозгу и построенной благодаря опыту и обучению.
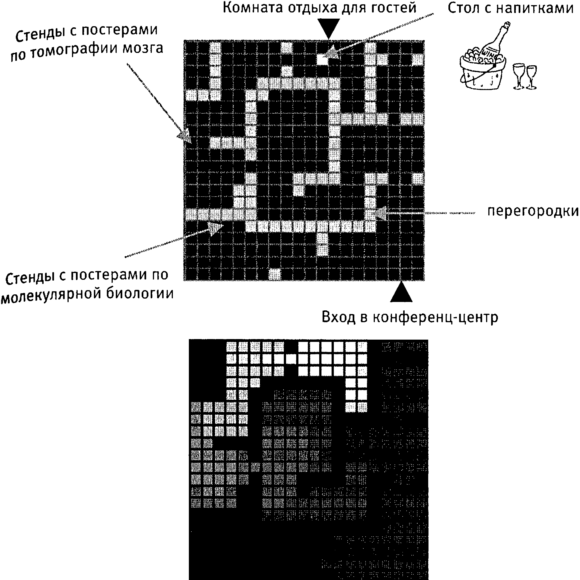
Рис. 4.5. Мозг представляет окружающий мир как пространство возможных наград (reward space).
Верхний рисунок: Карта конференц-центра. Составленная моим мозгом карта конференц-центра как пространства потенциальных наград.
Нижний рисунок: Я прибыл в незнакомый конференц-центр без карты. Стол с напитками скрыт за несколькими перегородками. Я могу найти его только методом проб и ошибок. После того, как я несколько раз нахожу стол с напитками, мой мозг создает карту конференц-центра как пространства потенциальных наград. Окраска отражает ценность (чем светлее, тем выше ценность). Если я буду двигаться в сторону участков, окрашенных светлее, я рано или поздно доберусь до стола с напитками. Но я не знаю, что руководствуюсь этой картой. Я просто иду к столу с напитками.
Вольфрам Шульц и специалисты по вычислительным системам Питер Даян и Рид Монтегю показали, что допаминовые нервные клетки ведут себя именно так, как следовало бы ожидать, исходя из того, что мозг обезьяны пользуется тем же методом обучения, что и машина, использующая алгоритм временных различий. Активность допаминовых клеток и отражает те ошибки в предсказаниях, которые позволяют обезьяне обучаться, не имея учителя. Этот механизм обучения работает отнюдь не только в нервных клетках обезьян. Обучением путем предсказаний можно объяснить также поведение пчел, которые ищут лучшие цветы, и людей, играющих в азартные игры.[99] В обоих случаях обучение путем предсказаний формирует карту возможных действий, на которой отмечено, какие действия с наибольшей вероятностью приведут к награде.
Составляемая мозгом карта мира
Пользуясь ассоциативным обучением, мозг составляет карту окружающего мира. По сути дела, это карта ценностей. На этой карте отмечены объекты, обладающие высокой ценностью, сулящие награду, и объекты, обладающие низкой ценностью, сулящие наказание. Кроме того, на ней отмечены действия, обладающие высокой ценностью, которые сулят успех, и действия, обладающие низкой ценностью, сулящие неуспех.
Стоя на пороге университетской столовой, я инстинктивно направляюсь туда, где смогу найти лучшую еду и напитки. Я направляюсь к столикам, за которыми обычно сидят мои друзья, и подальше от столиков, за которые часто садятся специалисты по молекулярной генетике и профессора английского языка. Я автоматически толкаю дверь, которая открывается вовнутрь, и прохожу, не задумываясь, туда, где подают горячее.[100] В какой-то момент администрация столовой может решить переставить столики и поменять дверь. Некоторое время я по-прежнему буду пытаться толкать дверь, которая теперь открывается наружу, но рано или поздно карта в моем мозгу будет автоматически подправлена.
Взяв свой обед, я сажусь за столик, и вскоре оказывается, как ни странно, что я сижу рядом с профессором английского языка и пытаюсь убедить ее, что все эти новые данные о том, как мозг познаёт окружающий мир, интересны и важны. Я говорю ей, что для нашего мозга окружающая действительность выглядит не какой-то звенящей разноцветной путаницей, а картой, на которой обозначены открытые перед нами возможности. И что эта карта открытых возможностей обеспечивает нашу глубокую связь с непосредственно окружающим нас миром. Стоит мне только увидеть вон ту кружку, как мой мозг уже начинает играть мышцами и сгибать мои пальцы на случай, если я захочу взять ее в руку.
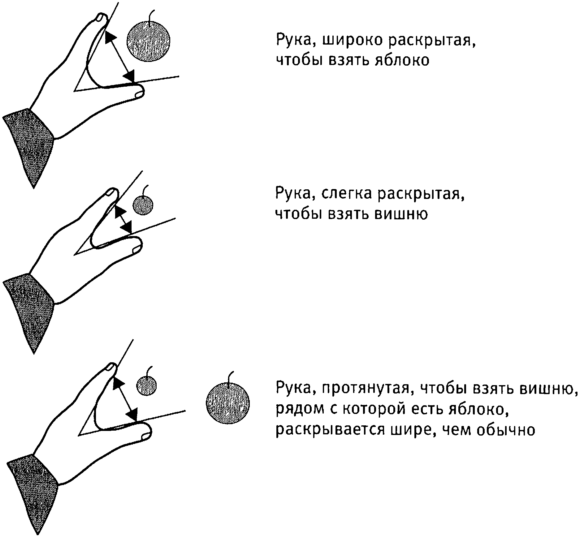
Рис. 4.6. Наш мозг автоматически готовит программы действий в соответствии с окружающими объектами.
Умберто Кастьелло и его коллеги провели ряд экспериментов, показавших, как различные находящиеся в поле зрения предметы вызывают автоматическую активацию реакций (программы действий), требуемых, чтобы протянуть руку и взять в нее каждый из этих предметов, даже если у человека нет осознанного намерения брать их в руки. Этот было сделано путем очень точного измерения движений рук испытуемых при взятии различных предметов. Когда мы берем что-либо рукой, расстояние между большим пальцем и остальными пальцами заранее приводится в соответствие с размером предмета. Когда я тянусь за яблоком, я раскрываю руку шире, чем когда тянусь за вишней. Но если я тянусь за вишней, в то время как на столе, кроме вишни, есть еще и яблоко, то я раскрываю руку шире, чем обычно делаю, чтобы взять вишню. Действие, требуемое, чтобы взять вишню, попадает под влияние действия, требуемого, чтобы взять яблоко. Такое влияние возможного действия на совершаемое показывает, что мозг одновременно параллельно заготавливает программы для всех этих действий.
Я объясняю ей, что именно так наше сознание и встраивается в материальный мир. Именно так наш мозг и изучает окружающий мир без помощи учителя. Я особенно стараюсь убедить ее, что эти идеи – не пустые слова и жесты. Эти идеи подтверждаются строгими математическими уравнениями.
"Неужели вы утверждаете, – отвечает она, – что где-то в моем мозгу есть карты всех мест, где я когда-либо была, и инструкции, как взять в руки все предметы, которые я когда-либо видела?"
Я объясняю ей, что в этом-то, наверное, и состоит самая замечательная особенность этих алгоритмов обучения. У нас есть только одна карта, а не последовательность карт, уходящая в далекое прошлое. У этой карты нет памяти. Она напоминает калейдоскоп, через который мы смотрим на мир. Пока наши предсказания выполняются, узор остается неизменным. Ошибочное предсказание встряхивает этот узор, чтобы на его месте возник новый. Это позволяет нам постоянно подстраивать свое поведение под изменчивый мир.
"Может быть, вы и живете одним настоящим, – отвечает она, – но я смотрю на мир совсем иначе. Мое сознание наполняют сожаления о прошлом и надежды на будущее, а не сиюминутные ощущения настоящего. А кроме того, – добавляет она, – может быть, ваше сознание и встроено в материальный мир, но мое встроено в мир культуры, создаваемый мыслями и чувствами других людей. Если я и воспринимаю материальный мир, то именно потому, что это вовсе и не я. Это, отчего мне больно, когда я спотыкаюсь ногой о камень".
На это я ничего не успеваю ответить, потому что она уходит читать свою заключительную лекцию по теме "Поток сознания".[101]
Это замечание профессора английского языка напоминает нам о разительном несоответствии между тем, что наш мозг знает об окружающем мире, и восприятием мира нашим сознанием. Ассоциативное обучение позволяет объяснить, как наш мозг приобретает знания о мире, но все это происходит и остается почти без нашего ведома. Что же тогда представляет собой наше восприятие окружающего мира, обеспечиваемое нашим мозгом?
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.