Глава G@C. Генетический код явление "героя" (X)
Глава G@C. Генетический код ? явление "героя" (X)
События, связанные с эволюцией Вселенной и коротко описанные выше, привели, в конечном счете (а может быть, и «в том числе») к возникновению жизни, центральным феноменом которой стало объединение мира нуклеиновых кислот и мира белков в единую автокаталитическую суперсистему, для чего потребовался и был доведен до необходимого состояния так называемый генетический код — связующее звено обоих миров. Генетический код — это набор инструкций для перевода нуклеотидной последовательности в полипептидную. Таким образом, сегодняшний код составляют два компонента. Первый — кодирующий —компонент — это четыреазотистых основания (или нуклеотида, когда они фосфорилированы и составляют цепи РНК или ДНК).
Общее обозначение азотистых оснований приведено в таблице:
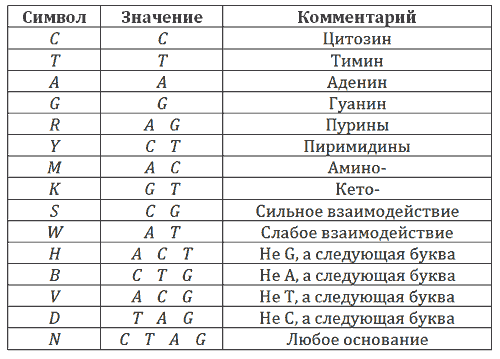
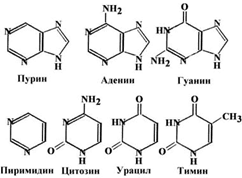
Из них состоит полинуклеотид — рибо- или дезоксирибонуклеиновая кислота, РНК или ДНК. В случае РНК четыре нуклеотида — это два пурина (аденин и гуанин в табличках
ниже) и два пиримидина -урацил и цитозин. В молекуле ДНК одно из перечисленных оснований — урацил — заменен на тимин (T):
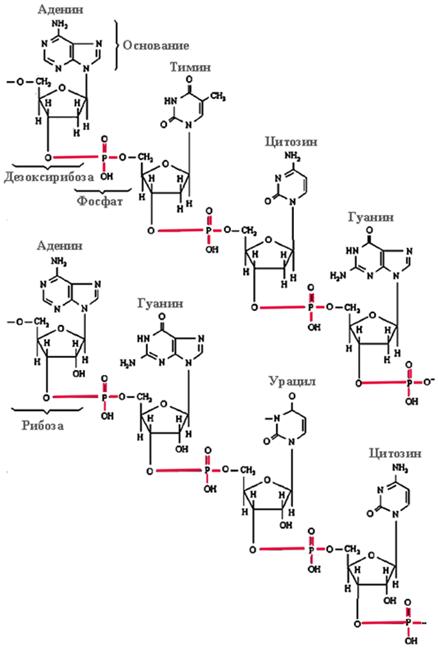
Полимером правовращающего сахара – рибозы или дезоксирибозы - в цепочку РНК или ДНК соединены трифосфаты этих оснований. Здесь показаны структуры одноцепочечных молекул ДНК (вверху) и РНК (внизу):
Второй — кодируемый — компонент генетического кода — этоаминокислоты, из которых состоят полипептиды или белки. Из более ста пятидесяти природных аминокислот кодируемыми являются только 20:
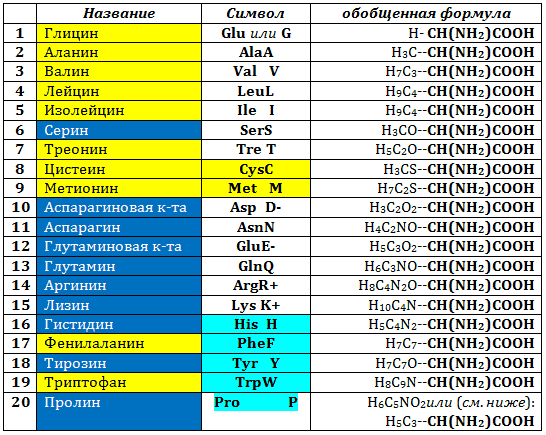
Для обозначения аминокислот (напомним, что кодируемыми являются альфа-L-аминокислоты) используют либо трех-, либо одно-буквенные символы; мы — как уже сказано — будем пользоваться последними. В таблице выделены гидрофильные (синие ячейки и белые буквы названий) и гидрофобные (желтые ячейки) аминокислоты, аминокислоты, способные нести заряд, отмечены знаками (+) или (-), ароматические аминокислоты (бирюзовые ячейки в колонке символов, иминокислотапролин — бирюзовое выделение); серусодержащие аминокислоты (желтые ячейки в колонке символов). В формуле молекул справа — одна и та же константная часть (участвующая в пептидной связи; полужирный шрифт), слева — боковая часть молекулы или радикал ®. Молекула пролина приведена к общей схеме гипотетическим размыканием (релаксацией) иминного кольца.
Очевидно, что аминокислоты отличаются друг от друга химической природой боковой цепи, которая состоит из группы атомов в молекуле аминокислоты, связанной с ?-углеродным атомом и не участвующей в образовании пептидной связи при синтезе белка. Всё разнообразие особенностей структуры и функции белковых молекул связано с химической природой и физико-химическими свойствами радикалов аминокислот. Именно благодаря им белки наделены рядом уникальных функций, не свойственных другим биополимерам, и обладают химической индивидуальностью. Благодаря им вновь синтезирующаяся полипептидная цепочка приобретает вторичную структуру, образуя определенной длины однотипные спирали, складчатость и повороты (изломы). Эта структура, в свою очередь, складывается в уникальную третичную, которая и обладает определенными функциями. Они могут быть усилены или модифицированы четвертичной белковой структурой, которую формируют уже не отдельные полипептиды, а их комбинация.
Это общие сведения (trivia) о компонентах генетического кода. Приводим его стандартную (каноническую) таблицу. Темно-серым выделены в ней кодирующие и кодируемые элементы группы вырожденности IVоктета 1 (см. ниже); светлым — элементыоктета 2 групп вырожденности I (темно-серые), III(светлее) иII (еще светлее). Чтобы подчеркнуть характер непосредственных участников процесса декодирования, то есть молекул РНК, четырьмя основаниями в таблице часто выбираются основания U, C, A и G. Именно на таком порядке настаивал Френсис Крик — не помню точно, почему, — может быть, потому, что, скажем, теория граничных орбиталей химической реактивности, которая была разработана для сравнения вероятностей стабилизации избыточных электронов для различных ДНК-составляющих, предсказывает снижение электронного сродства и потенциалов ионизации, подтверждаемое экспериментальными данными, именно в порядке T>C>А>G[50].
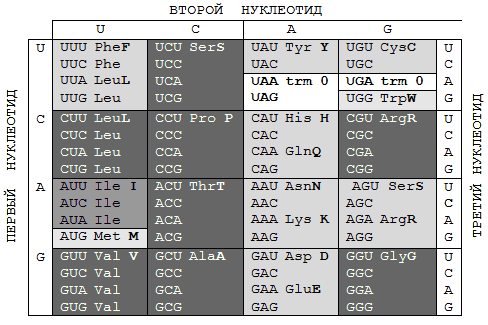
Функция молекулы ДНК — не декодироание, но хранение генетической информации. Поскольку выбор «главной» из этих двух функций — задача очевидно нелепая, таблицы кода с основаниями Т, C, A и G встречаются не менее часто.
Напомним теперь восемь основных свойств генетического кода, определяющих сопоставление нуклеотидов и аминокислот, и девятое — альтернативное.
? Первое из них — триплетность, означающая, что каждую используемую в живых структурах аминокислоту кодируют три последовательно (то есть от 5`- к 3`-концу цепи) расположенных азотистых основания. Их называют триплетом или кодоном. В таблице первым двум основаниям соответствуют вертикальная и горизонтальная координаты; третье основание показано по вертикали справа и делает «таблицу» трехмерным кубом 4?4 х 4.
? Физических промежутков между кодонами нет, поскольку код характеризуется непрерывностью. Если бы код был синглетным, то есть если бы каждой кодируемой аминокислоте соответствовало бы только одно основание (из четырех), кодирующая емкость кода и составляла бы только четыре аминокислоты. Между тем, таких аминокислот двадцать, и только этого числа (не меньше!) достаточно для обеспечения существующего белкового разнообразия. Если бы код был дублетным, то есть если бы каждой кодируемой аминокислоте соответствовало бы два основания, кодирующая емкость кода составляла бы только шестнадцать аминокислот (42) — и этого недостаточно. Емкость триплетного кода составляет 64 аминокислоты (43). Этого хватает с избытком. «Избыток» составляет 44 кодируемых продукта. Многие исследователи утверждают, что эволюция генетического кода шла в направлении от синглетного к триплетному. При этом они понимают, что смена размера кодирующей единицы потребовала бы принципиального изменения всей машины кодирования (то есть всего набора ферментов, обслуживающих этот процесс) — вещь невозможная! Поэтому синглетный этап кодирования мог означать, что в составе триплета значащей единицей могла быть только одна (например, первая или любая), а в составе дублета — две. Тогда и непрерывность кодированной записи могла быть только физической. Функционально значащие основания разделялись остальными основаниями триплета, а эволюция продолжала совершенствовать структуру молекул-участников кодирования. Произвольные (из четырех) третьи основания современных кодонов для восьми (из двадцати) аминокислот могут быть реликтами до-триплетных кодов. Выбор же тройки азотистых оснований в качестве дискретной единицы генетического кода мог быть обусловлен также термодинамикой взаимодействия пар оснований, при котором матричное копирование инициируется их триплетом (мы говорили об этом выше, ссылаясь на Зенгера).
? Неперекрываемость — один и тот же нуклеотид не может входить одновременно в состав двух или более триплетов; не соблюдается для некоторых перекрывающихся генов вирусов, митохондрий и бактерий, которые кодируют несколько белков, считывающихся со сдвигом рамки.
? Поскольку никакого избытка в крайне экономной природе не бывает, он и здесь компенсируется еще одним свойством — вырожденностью (избыточностью), означающую, что каждую аминокислоту (два исключения — метионин и триптофан) кодирует более, чем один триплет. Красным цветом выделены клетки таблицы, содержащие аминокислоту, кодируемую четырьмя триплетами, оранжевым — тремя, желтым — двумя, зеленым — две аминокислоты, кодируемые только одним триплетом.
? Однозначность кода означает, что каждый триплет фрагмента полинуклеотида, именуемого геном, кодирует только одну аминокислоту. Продуктами кодирования являются не только аминокислоты, но и знаки пунктуации — знак начала кодирующей цепочки (гена), ATG, или AUG, называемые стартовыми кодонами, и знаки ее окончания — TAA (UAA), TAG (UAG) и TGA (UGA) или стоп-кодоны (в таблице — буквы синего цвета в бесцветных ячейках). Начало гена — это всегда аминокислота (метионин в данном случае), конец его — аминокислота, предшествующая стоп-кодону.
? Еще одно свойство генетического кода — универсальность, означает, что все живущие на Земле существа — будь то РНК- или ДНК-вирус, слон, морковка, червь или человек — пользуются одним и тем же генетическим кодом. Немногочисленные отклонения от этого правила касаются лишь отдельных аминокислот и являются, скорее всего, именно отклонениями, результатом весьма длительной эволюции в специфических условиях.
? Небольшое число таких отклонений лишь подчеркивают шестое из перечисляемых свойств кода — необычайная стабильность.
? За этим свойством неизбежно должно стоять — и стоит — еще одно — столь же необычайная помехоустойчивость. Помехоустойчивость относится к двум наиболее важным свойствам кодируемых аминокислот — их размеру, который характеризуется объемом или массой молекулы, и их гидрофильности (и гидрофобности), которые определяют вторичную структуру полипептида. Замена третьего основания триплета, как правило, не влияет на эти свойства, замена второго более существенна и относится, по преимуществу, к гидрофильности аминокислоты или к ее гидрофобности, замена первого может оказаться роковой; она меняет размер кодируемой молекулы. Если подсчитать, сколько замен одного нуклеотида не меняет тип аминокислоты в соответствии с ее химическими свойствами (а такие замены аминокислот слабо сказываются на структуре и функциях белка) и сколько меняет, то отношение первых ко вторым будет близко к 2,25. Расчеты показывают, что существующий генетический код не является самым оптимальным вариантом кода по признаку помехоустойчивости, и специальными программами удается сгенерировать еще более устойчивые в этом отношении коды. Тем не менее, компьютерное моделирование демонстрирует вполне впечатляющую частоту кодов со сходной с существующим помехоустойчивостью — один на миллион. Даже при такой частоте число помехоустойчивых кодов еще достаточно велико, чтобы вызывать впечатление случайности выбора той версии, которая используется на Земле. А так и не достигнутый за миллиарды лет максимум помехоустойчивости генетического кода на нашей планете наводит на мысль о том, что этому препятствовало какое-то нетривиальное правило, ограничивавшее его эволюцию в данном направлении.
? И еще одно свойство, характеризующее обсуждаемый генетический код и отмеченное Френсисом Криком, заключается в следующем. Поскольку ни изощренные и длительные эксперименты, ни теория — во времена Крика — не показывали абсолютно никакого физико-химического соответствия между нуклеотидными триплетами и аминокислотами, он назвал не поддающийся изменениям в течение миллиардов лет генетический код замороженной случайностью. Замороженной — в том смысле, что сформировавшись, он уже не менялся. Случайностью — в том смысле, что он мог сформироваться каким угодно. А вот то, что он сформировался именно таким, каким мы его видим, и настолько удачно, что в дальнейшем мог уже и не меняться, придает ему, на первый взгляд, свойство чуда. На сегодняшний день оценка Крика — едва ли не самая убедительная гипотеза происхождения генетического кода. И все-таки, когда мы говорим «случайность», рассматривая формальные свойства кода (мы сделаем это позднее), не только физика и химия приходят нам в голову. Но и они (физика и химия) предлагают сегодня альтернативную замороженной случайности гипотезу, гипотезу «ключ-замок», основанную на экспериментальных данных, которые все же показывают определенное сродство отдельных аминокислот с отдельными РНК-последовательностями. Об этом — в конце книги.
.....................
«Номер» этой главы назван «инициалами» ее «главного героя» — GeneticCode. Автор хотел, однако, не только отметить их совпадение с принятым обозначением пары гуанин-цитозин (GC), но акцентировать комплементарность этой пары, которую в названии главы подчеркивает вторая комплементарная пара — аденин-тимин (АТ), символ которой (предлог at) обозначается на «компьютерном языке» знаком @. Если пару АТ встроить между G и C вся четверка — G>А>||>Т>C— оказывается упорядоченной по массе и зеркально симметричной по комплементарности относительно центра, отмеченного двумя короткими вертикалями. В составе двуцепочечной молекулы нуклеиновой кислоты пара GC демонстрирует сильное, S, взаимодействие, образуя три межнуклеотидных водородных связи C?G (нижняя пара на рисунке), в то время, как пара АТ (верхняя часть рисунка, A=T) демонстрирует слабое, W, взаимодействие:
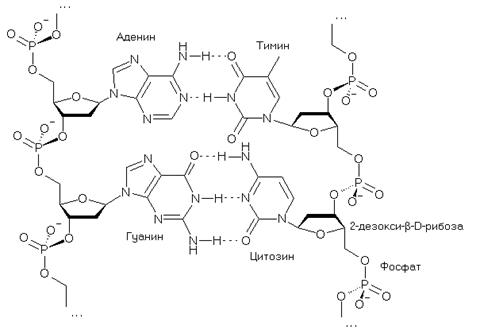
Результатом комплементарности пар оснований является первое правило Чаргаффа: число гуанинов (G) в двуцепочечной ДНК равно числу цитозинов (С), а число аденинов (А) равно числу тиминов (Т). Это правило стало одним из краеугольных камней открытия спиральной структуры этой молекулы, о чем можно прочитать в любом учебнике.
Позднее мы коротко коснемся и так называемого второго правила Чаргаффа, которое относится только к одной природной полинуклеотидной цепи. Существуют и некомплементарные взаимодействия пар оснований — «качающиеся» и хугстеновские (см. ниже). В природе все намного интереснее и богаче, чем в учебнике. Мы не можем обусловить начало жизни только формированием генетического кода (тогда ее дефиниция оказалась бы не слишком трудной задачей и упомянутое выше следствие теоремы Гёделя удалось бы обойти), какие-то свойства жизни мы различаем и до этого события, но беспрецедентная универсальность кода — при физико-химической произвольности — делает его едва ли не главной меткой нуклеиново-белковой жизни. И далее мы будем говорить именно о генетическом коде.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Глава 3 Мужчина как явление природы
Глава 3 Мужчина как явление природы Думается, что мир без мужчин был бы прекрасен. Не было бы оружия, исход войн решался бы на подиумах, а автомобили без встроенной косметички были бы запрещены к производству. Но в определенный период развития жизни на Земле что-то пошло не
4.2. Генетический анализ
4.2. Генетический анализ Совокупность методов изучения наследственности получила название «генетический анализ». Его основа – гибридологический метод, разработанный Г. Менделем. С открытия законов наследования Г. Менделем и начинается история генетики. Не меньшая
6.2. Генетический код
6.2. Генетический код Генетическая информация записывается последовательностями нуклеотидов в нуклеиновых кислотах с помощью 4 символов, как информация текста книги записывается с помощью букв, количество которых зависит от конкретного алфавита. В структуру белка эта
ГЕНЕТИЧЕСКИЙ АНАЛИЗ
ГЕНЕТИЧЕСКИЙ АНАЛИЗ В 1980 годах профессор Алек Джеффрис из Лестерского университета доказал наличие многочисленных участков ДНК, которые не следует считать кодом аминокислот. Эти участки назвали минисателлитные ДНК. Тысячи ДНК разбросаны по всем хромосомам; возможно,
Глава G@C. Генетический код явление "героя" (X)
Глава G@C. Генетический код ? явление "героя" (X) События, связанные с эволюцией Вселенной и коротко описанные выше, привели, в конечном счете (а может быть, и «в том числе») к возникновению жизни, центральным феноменом которой стало объединение мира нуклеиновых кислот и мира
Болезнь как индивидуальное явление
Болезнь как индивидуальное явление «Изменчивость — строительный материал эволюции. Это не случайное отклонение от нормы, а основное свойство природы. Изменчивость — основа всего сущего, постоянство же иллюзорно. Биологический вид представляет собой группу особей с
Бесстрашие (Mut) как стадное явление
Бесстрашие (Mut) как стадное явление Эммануил Кант определил («Антропология в прагматическом смысле») бесстрашие следующим образом: Бесстрашие — это душевное состояние, необходимое для обдуманного принятия на себя опасности. Нормальной биологической реакцией на
Какое явление моряки называют мертвой водой?
Какое явление моряки называют мертвой водой? Мертвая вода – это явление в морях, связанное с сильным опреснением тонкого поверхностного слоя воды и образованием резкого перепада плотности на границе между этим слоем и лежащими под ним более плотными (более солеными)
Генетический код
Генетический код Поскольку информация о структуре белков в ДНК и и-РНК записана последовательностью нуклеотидов, для перезаписи в последовательность аминокислот должна существовать система кодировки, которая получила название «генетический код».Генетический код –
Явление педоморфоза в антропогенезе
Явление педоморфоза в антропогенезе Открытие роли явлений гетерохронии в эволюции послужило основой для различных гипотез, объясняющих эволюционные аспекты морфогенеза. Применительно к человеку была предложена теория голландского ученого Луи Болька об эволюции
Глава 14. Генетический Армагеддон: «Терминатор» и патенты на свинину
Глава 14. Генетический Армагеддон: «Терминатор» и патенты на свинину «Монсанто» окончательно поглощает «Дельта эн Пайн Ланд» В летний августовский день 2006 года, пока весь мир развлекался на каникулах и в отпусках, произошло корпоративное приобретение, которое должно
Глава 4 Пол и генетический мятеж
Глава 4 Пол и генетический мятеж Черепаха живет между двух пластин, Она или он — вид один. Черепаха, я думаю, очень умна, Раз так, притом, плодовита она. Огден Нэш (пер. О. Волковой). В средневековых английских деревнях одно пастбище было общинным. Каждый имел право пасти
Генетический пол
Генетический пол Первым в списке Мани значится хромосомный (или генетический) пол. Генетические различия между мужским и женским полом представляют собой фундаментальную основу феномена пола, отражающую важнейшую черту полового размножения. У подавляющего большинства
Гомосексуализм как культурное явление
Гомосексуализм как культурное явление Эволюционная теория предполагает, что адаптивные признаки должны воспроизводиться более успешно, чем неадаптивные. Важным индикатором адаптивности признака является его положительное влияние на репродукцию и воспроизводство