Глава 3 Накопление небольших изменений
Глава 3
Накопление небольших изменений
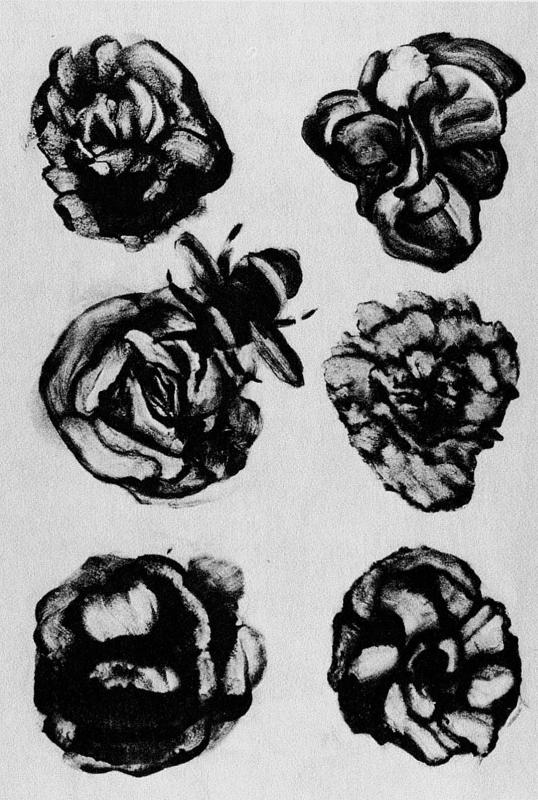
Итак, живые существа столь невероятны и столь превосходно “продуманны”, что не могли возникнуть случайно. Тогда каким же образом они возникли? Ответ, по Дарвину, таков: путем постепенного, пошагового преобразования простейших первопричин; из зачаточных элементов, которые были достаточно просты для того, чтобы возникнуть случайно. Каждое очередное изменение в ходе постепенного эволюционного процесса было достаточно простым по сравнению с непосредственным предшественником и потому могло произойти спонтанно. Однако, подумав о том, каким сложным по сравнению с примитивным исходным материалом оказался конечный результат, понимаешь, что вся совокупность последовательных шагов была процессом далеко не случайным. Двигателем накопления изменений является неслучайное выживание. Задача этой главы показать, на что способен накапливающий отбор — явление, не имеющее со случайностью ничего общего.
Прогуливаясь по галечному пляжу, вы можете заметить, что галька лежит не беспорядочно. Мелкие камешки обычно группируются в виде обособленных полос, тянущихся вдоль пляжа, а более крупные — отдельно от них. Они сортировались, распределялись, отбирались. Какое-нибудь прибрежное племя могло бы удивиться такому свидетельству продуманности и упорядоченности мира и сложить миф, который объяснял бы этот феномен, скажем, волей Великого Духа, живущего на небесах, чей разум склонен к аккуратности и порядку. Мы снисходительно улыбнулись бы на такое суеверие и объяснили бы, что на самом деле порядок здесь навели слепые силы физики — в данном случае морские волны. Волнам несвойственно иметь цели и намерения, их разум не склонен к аккуратности — у них вообще нет разума. Они просто приносят энергию, которая разбрасывает гальку по пляжу, а мелкие и крупные камни по-разному реагируют на такое воздействие и потому оказываются на разном расстоянии от воды. Из беспорядка возникла малая толика порядка, и ничей разум этого не планировал.
Волны и галька образуют простую систему, автоматически генерирующую неслучайность. Таких систем в мире полным-полно. Наипростейший пример, приходящий мне в голову, — это дыра. Через дыру проходят только те предметы, которые меньше ее. Это значит, что если изначально вы располагаете неким случайным набором объектов над дырой, а также некоей силой, которая перетряхивает эти объекты случайным образом, то через некоторое время объекты выше и ниже дыры будут рассортированы отнюдь не бессистемно. Пространство под дырой будет иметь тенденцию содержать в себе объекты меньше дыры, а пространство над дырой — те объекты, которые превосходят ее по размерам. Конечно же, люди давным-давно научились извлекать выгоду из этого простого принципа генерирования неслучайности, лежащего в основе такого полезного приспособления, как сито.
Наша Солнечная система представляет собой стабильное и организованное объединение планет, комет и всяческих обломков, вращающихся вокруг Солнца, и предположительно является одной из многих подобных систем во Вселенной. Чем ближе к Солнцу находится космическое тело, тем с большей скоростью оно должно двигаться, чтобы противостоять силе гравитации и оставаться на устойчивой орбите. Для любой отдельно взятой орбиты существует только одна скорость, с которой можно лететь, не сходя с этой орбиты. Двигаясь с любой другой скоростью, тело либо умчится далеко в космос, либо перейдет на другую орбиту, либо рухнет на Солнце. Взглянув на планеты Солнечной системы, мы с вами увидим, что — ну надо же! — каждая из них перемещается вокруг Солнца с той самой скоростью, которая необходима, чтобы оставаться на орбите. Благословенное чудо дальновидного замысла? Нет, просто еще одно природное “сито”. Очевидно, что все вращающиеся вокруг Солнца планеты, которые мы наблюдаем, должны двигаться по своим орбитам именно с нужной скоростью, иначе бы мы их там не видели, поскольку их бы там не было! Но точно так же очевидно и то, что в этом нет никакого доказательства сознательного замысла. Перед нами просто еще одна разновидность сита.
Подобное примитивное отсеивание само по себе ни в коей мере не является достаточным для объяснения той высочайшей степени упорядоченности, какую мы видим в живых организмах. Давайте вспомним аналогию с кодовым замком. Тот уровень неслучайности, который может быть достигнут простым отсеиванием, можно с натяжкой приравнять к открытию кодового замка с кодом из одной цифры — такой легко может быть открыт исключительно наудачу. То же, что мы можем наблюдать в живых системах, аналогично громадному кодовому замку с практически бесконечным числом угадываемых цифр. Произвести биологическую молекулу типа гемоглобина (красного кровяного пигмента) путем простого “просеивания” — это было бы равносильно тому, чтобы взять все аминокислотные “строительные блоки” для гемоглобина, встряхнуть их и надеяться, что молекула гемоглобина соберется сама собой. Везение, которое тут потребуется, долж но быть просто невообразимым — вот почему Айзек Азимов и прочие так любят приводить этот пример в качестве убойного аргумента.
Молекула гемоглобина состоит из четырех аминокислотных цепочек, переплетенных между собой. Возьмем только одну из них. Она образована 146 аминокислотами. В живых организмах обычно встречается 20 разных типов аминокислот. Число способов, которыми можно соединить 20 различных элементов в цепь длиной в 146 звеньев, невероятно велико; Азимов назвал его “гемоглобиновым числом”. Его несложно подсчитать, но вот вообразить затруднительно. Первым звеном из 146 может оказаться любая из 20 допустимых аминокислот. Вторым тоже. Следовательно, для цепочек, состоящих из двух звеньев, количество возможных вариантов равняется 20 ? 20, то есть 400. Число возможных типов цепочки из трех звеньев будет 20 ? 20 ? 20, что равняется 8000. Чтобы узнать, сколько может быть построено различных цепочек из 146 звеньев, надо 146 раз помножить двадцатку саму на себя. Полученное число будет ошеломляюще громадным. Миллион — это единица с шестью нулями. Миллиард (1000 миллионов) — это единица с девятью нулями. А искомое нами число — “гемоглобиновое число” — это (приблизительно) единица со 190 нулями после нее! И только один из этого множества вариантов — наш гемоглобин. Вот сколь ничтожен шанс получить его благодаря удачному стечению обстоятельств. А ведь молекула гемоглобина — это лишь крохотная частица сложнейшего устройства. Совершенно очевидно, что само по себе простое отсеивание даже близко не в состоянии порождать ту степень упорядоченности, какую мы видим в живых организмах. Отсеивание — важный фактор при формировании сложной организации живого, но это далеко не все, что требуется. Нужно что-то еще. Чтобы объяснить, что же именно, мне необходимо провести разграничение между “одноступенчатым” и “накапливающим” отбором. Все те примитивные разновидности сита, которые мы пока что рассматривали в этой главе, представляют собой примеры одноступенчатого отбора. А живые организмы являются результатом накапливающего отбора.
Принципиальное различие между двумя этими видами отбора состоит в следующем. При одноступенчатом отборе отбираемые или сортируемые объекты — будь то камешки на пляже или что-то другое — отбираются раз и навсегда. А при отборе накапливающем они “размножаются” — ну или каким-то иным способом результаты одного отсеивания оказываются материалом для другого, следующего отсеивания, результаты которого опять “проходят через сито”, и так далее до бесконечности. Объекты подвергаются отбору или систематизации в течение многих следующих друг за другом “поколений”. Итоги отбора в одном поколении являются отправной точкой для отбора в следующем поколении, и так много поколений подряд. Использовать тут слова “размножаться” и “поколение”, обычно применимые к живым организмам, вполне естественно, ведь живые организмы — это самый типичный пример объектов, участвующих в процессе накапливающего отбора. В реальности они могут оказаться даже единственным таким примером, но пока я предпочел бы воздержаться от категоричных заявлений.
Порой игра ветра придает облакам форму легкоузнаваемых предметов. Много раз публиковалась фотография, сделанная одним пилотом-любителем: нечто похожее на глядящий с неба лик Иисуса. Все мы видели облака, которые были на что-нибудь похожи, например на морского конька или на улыбающуюся рожицу. Эти изображения возникают путем одноступенчатого отбора — другими словами, благодаря однократному совпадению, — и потому большого впечатления они не производят. Сходство знаков зодиака с животными, в честь которых они были названы, — Скорпион, Лев и т. п. — не более интересно, чем предсказания астрологов. Оно не ошеломляет нас в той же степени, что и биологические адаптации, возникающие в результате накапливающего отбора. Увидев, сколь схожа листовидка с листом, или встретив богомола, выглядящего как соцветие из розовых цветочков, мы описываем эти явления как необычайные, поразительные и захватывающие дух. А если облако похоже на хорька, то для нас это разве что слегка занятно и едва ли стоит того, чтобы обращать внимание собеседника. Более того, мы вполне можем изменить свое мнение насчет того, на что это облако больше всего похоже.
ГАМЛЕТ. Видите вы вон то облако в форме верблюда?
ПОЛОНИЙ. Ей-богу, вижу, и действительно, ни дать ни взять верблюд.
ГАМЛЕТ. По-моему, оно смахивает на хорька.
ПОЛОНИЙ. Правильно: спинка хорьковая.
ГАМЛЕТ. Или как у кита.
ПОЛОНИЙ. Совершенно как у кита[1].
Не знаю, кто именно первым обратил наше внимание на то, что обезьяна, бессмысленно лупящая по пишущей машинке, смогла бы, имей она достаточно времени, напечатать полное собрание сочинений Шекспира. Ключевая фраза тут, разумеется, “имей она достаточно времени”.
Давайте слегка облегчим задачу нашей обезьяне. Пусть ей надо будет напечатать не полное собрание сочинений, а всего лишь коротенькое предложение Methinks it is like a weasel (“По-моему, оно смахивает на хорька”), и, чтобы облегчить задачу еще больше, мы дадим ей для этого упрощенную клавиатуру, содержащую только 26 букв (заглавных) и клавишу пробела. Сколько же времени на это потребуется?
В выбранном предложении 28 знаков. Давайте будем считать, что обезьяна как бы делает серию дискретных “попыток”, каждая из которых состоит из 28 ударов по клавиатуре. Если она правильно набирает нужную фразу — эксперимент окончен. Если нет — мы даем ей новую “попытку” 28 раз нажать на клавиши. Я не знаком ни с одной обезьяной, но, к счастью, моя 11-месячная дочь представляет собой хорошо зарекомендовавший себя в деле генератор беспорядка, и она с готовностью (даже, может быть, излишней) согласилась взять на себя роль обезьянки-машинистки. Вот что она набрала на компьютере:
UMMK JK CDZZ F ZD DSDSKSM
S SS FMCV PU I DDRGLKDXRRDO
RDTE QDWFDVIOY UDSKZWDCCVYT
H CHVY NMGNBAYTDFCCVD D
RCDFYYYRM N DFSKD LD K WDWK
JJKAUIZMZI UXDKIDISFUMDKUDXI
Однако у нее много дел и без того, так что я был вынужден запрограммировать компьютер так, чтобы он сам имитировал печатающего младенца или обезьяну:
WDLDMNLTDTJBKWIRZREZLMQCO P
Y YVMQKZPGJXWVHGLAWFVCHQYOPY
MWR SWTNUXMLCDLEUBXTQHNZVJQF
FU OVAODVIKDGXDEKYVMOGGS VT
HZQZDSFZIHIVPHZPETPWVOVPMZGF
GEWRGZRPBCTPGQMCKHFDBGW ZCCF
И так далее, и тому подобное. Вычислить, через какое время имеет смысл ожидать, что компьютер (или младенец, или обезьяна) случайно наберет METHINKS IT IS LIKE A WEASEL, нетрудно. Давайте прикинем общее число возможных фраз нужной нам длины, которые обезьяна, или младенец, или компьютер могли бы случайно набрать. Принцип расчета будет тот же самый, что и для гемоглобина, и результат получится таким же огромным. На месте первой буквы может оказаться любая из имеющихся 27 (давайте считать пробел тоже “буквой”). Таким образом, шансы, что обезьяна в качестве первой буквы поставит нужную нам M, составляют 1 из 27. Вероятность того, что правильными окажутся первые две буквы ME, будет равна вероятности правильного попадания на вторую букву E (1 из 27) при условии, что первая буква, M, уже оказалась верной — то есть 1/27 ? 1/27 или 1/729. Вероятность получить первое слово, METHINKS, соответствует 1/27 для каждой из восьми составляющих его букв, иначе говоря, 1/27 ? 1/27 ? 1/27 … и т. д., всего восемь раз, то есть 1/27 в 8-й степени. Вероятность же написать правильно всю фразу из 28 знаков составляет 1/27 в 28-й степени, что означает число 1/27, помноженное само на себя 28 раз. Это очень маленькие шансы, где-то 1 к 10 000 миллионов миллионов миллионов миллионов миллионов миллионов. Ждать нужной фразы придется, мягко выражаясь, очень-очень долго. Что уж говорить о полном собрании сочинений.
Вот и все, на что способен одноступенчатый отбор случайных изменений. А как насчет накапливающего отбора, намного ли он будет эффективнее? Очень намного — возможно, больше, чем мы в состоянии вообразить, хотя если подумать, то это покажется почти что очевидным. Мы снова воспользуемся нашей компьютерной обезьянкой, но внесем в программу одно существенное изменение. Как и в предыдущий раз, компьютер начинает со случайной 28-буквенной последовательности:
WDLDMNLTDTJBKWIRZREZLMQCOP
А затем приступает к “селекции”. Он воспроизводит эту бессмысленную фразу несколько раз подряд, но с определенной вероятностью случайной ошибки — “мутации” — при копировании. Далее компьютер изучает получившиеся бессмысленные фразы — “потомство” исходной — и выбирает среди них ту, которая хоть сколько-нибудь больше других походит на искомое METHINKS IT IS LIKE A WEASEL. В данном случае среди следующего “поколения” победительницей оказалась такая фраза:
WDLTMNLTDTJBSWIRZREZLMQCO P
Не то чтобы явное улучшение! Но алгоритм продолжает выполняться, теперь уже эта фраза “производит” мутантное “потомство”, из которого выбирается новый “победитель”. Десять поколений спустя фраза, оставляемая “на племя”, выглядела так:
MDLDMNLS ITJISWHRZREZ MECS P
А по прошествии 20 поколений она была такой:
MELDINLS IT ISWPRKE Z WECSEL
К этому времени предубежденному взгляду уже начинает мерещиться сходство с нужной фразой. Спустя 30 поколений никаких сомнений не остается:
METHINGS IT ISWLIKE B WECSEL
Сороковое поколение отделяет от цели всего одна буква:
METHINKS IT IS LIKE I WEASEL
Цель была окончательно достигнута в 43-м поколении. Второй заход компьютер начал с фразы:
Y YVMQKZPFJXWVHGLAWFVCHQXYOPY, —
прошел через следующие промежуточные стадии (я снова привожу только каждое десятое поколение):
Y YVMQKSPFTXWSHLIKEFV HQYSPY
YETHINKSPITXISHLIKEFA WQYSEY
METHINKS IT ISSLIKE A WEFSEY
METHINKS IT ISBLIKE A WEASES
METHINKS IT ISJLIKE A WEASEO
METHINKS IT IS LIKE A WEASEP —
и достиг конечной фразы в поколении 64. В третий раз он начал так:
GEWRGZRPBCTPGQMCKHFDBGW ZCCF —
и пришел к METHINKS IT IS LIKE A WEASEL за 41 поколение направленной “селекции”.
Какое именно время потребовалось компьютеру для достижения цели — не имеет значения. Если вам интересно, в первый раз он справился с задачей, пока я выходил пообедать. То есть где-то за полчаса. (Читатели, увлекающиеся компьютерами, сочтут это неоправданно долгим. Причина в том, что программа была написана на бейсике — компьютерной разновидности детского лепета. Когда я переписал ее на паскале, выполнение заняло 11 секунд.) В таких делах компьютеры несколько проворнее обезьян, но на самом деле разница не принципиальна. Что действительно существенно, так это разница между сроком, потребовавшимся для накапливающего отбора, и тем промежутком времени, который потребовался бы для достижения той же самой цели тому же самому компьютеру, работающему точно с такой же скоростью, но методом одноступенчатого отбора: около миллиона миллионов миллионов миллионов миллионов лет. Это более чем в миллион миллионов миллионов раз больше сегодняшнего возраста Вселенной. Лучше даже будет сказать так: по сравнению с тем временем, которое понадобится обезьяне или компьютеру, чтобы случайно набрать нужную фразу, нынешний возраст вселенной — пренебрежимо малая величина, столь малая, что наверняка попадает в пределы погрешности, допускаемой нами в наших приблизительных вычислениях. А компьютеру, работающему тоже наугад, но при ограничивающем условии накапливающего отбора, для выполнения той же задачи потребуется срок, вполне доступный простому человеческому пониманию: от 11 секунд до времени, необходимого, чтобы пообедать.
Итак, отличие накапливающего отбора (когда любое усовершенствование, каким бы незначительным оно ни было, служит фундаментом для дальнейшего строительства) от одноступенчатого (когда каждая новая “попытка” начинается “с чистого листа”) очень велико. Если бы эволюционный прогресс опирался на одноступенчатый отбор, это вряд ли привело бы хоть к чему-нибудь. Если бы, однако, слепым силам природы удалось каким угодно образом создать условия, благоприятные для накапливающего отбора, то последствия оказались бы необыкновенными и изумительными. Собственно говоря, именно это произошло на нашей планете, а сами мы принадлежим к числу самых недавних из таких последствий — и едва ли не самых необыкновенных и изумительных.
Забавно, что расчеты наподобие того, который я привел для “гемоглобинового числа”, все еще используются в качестве аргументов против дарвиновской теории. По-видимому, те, кто так делает, будучи зачастую квалифицированными специалистами в своей области — астрономами или кем угодно еще, искренне думают, что дарвинизм объясняет устройство живых организмов одной лишь случайностью, пресловутым “одноступенчатым отбором”. Убеждение, будто дарвиновская эволюция “случайна”, не просто неверно. Оно диаметрально противоположно истине. В дарвиновском рецепте используется лишь крупинка случайности, а основной ингредиент — это накапливающий отбор, который по сути своей неслучаен.
Облака не способны участвовать в процессе накапливающего отбора. Не существует такого механизма, посредством которого они могли бы производить выводки подобных себе дочерних облаков. Если бы такой механизм был, если бы облако, похожее на хорька или на верблюда, могло стать родоначальником клана облаков примерно той же формы, тогда у накапливающего отбора появился бы шанс приняться за дело. Разумеется, облака порой распадаются на части и образуют “дочерние” облака, но для накапливающего отбора этого недостаточно. Необходимо также, чтобы “потомство” любого отдельно взятого облака было похоже на своего “родителя” больше, чем на любого из более далеких “предков” в “популяции”. Некоторым из философов, заинтересовавшихся в последние годы теорией естественного отбора, этот ключевой момент явно непонятен. Далее нужно, чтобы вероятность выживания облака и производства им собственных копий как-то зависела от его формы. Возможно, в некоей далекой галактике такие условия возникли и по прошествии достаточного количества миллионов лет дали начало воздушной, бестелесной форме жизни. Из этого мог бы выйти неплохой научно-фантастический роман — под названием, скажем, “Белое облачко”, — но для наших нынешних целей компьютерная модель с обезьяной и Шекспиром более наглядна.
Хотя наша модель “обезьяна/Шекспир” и годится для демонстрации отличий одноступенчатого отбора от накапливающего, в некоторых важных отношениях она неудачна и может ввести в заблуж дение. Например, в каждом поколении направленной “селекции” мутантное “потомство” оценивалось по критерию соответствия далекому идеалу — фразе METHINKS IT IS LIKE A WEASEL. В жизни же все иначе. У эволюции нет долгосрочных стремлений. Сколько бы человеческое тщеславие ни лелеяло абсурдную идею, будто наш вид и есть конечная цель творения, не существует ни отдаленной цели, ни окончательного совершенства, которое могло бы послужить мерилом для отбора. В реальной жизни критерии для отбора всегда краткосрочны — это либо простое выживание, либо, в более общем смысле, репродуктивный успех. Если по прошествии геологических эпох свершается то, что задним числом выглядит как движение к некоей далекой цели, это всегда побочный результат сиюминутного отбора, действовавшего в течение многих поколений. “Часовщик”, коим является накапливающий естественный отбор, не видит будущего и не ставит перед собой никаких долгосрочных задач.
Принимая это во внимание, мы можем изменить нашу компьютерную модель. Также мы можем приблизить ее к реальности и в других аспектах. Буквы и слова — это проявления сугубо человеческой природы, так что лучше пускай наш компьютер рисует картинки. Возможно, нам даже удастся увидеть, как изображения на экране благодаря накапливающему отбору мутантных форм приобретают очертания, напоминающие животных. Мы не будем предрешать исход дела, вводя в программу изображения животных в качестве стартового материала. Нам хотелось бы, чтобы они возникли сами и исключительно в результате накапливающего отбора случайных мутаций.
В реальной жизни внешний вид животного возникает в процессе эмбрионального развития. Эволюция происходит потому, что в ряду сменяющих друг друга поколений эмбриональное развитие слегка варьирует. Эти небольшие отклонения появляются вследствие изменений в генах, контролирующих развитие (мутации — та самая необходимая крупица случайности, о которой я упоминал). Следовательно, в нашей компьютерной модели должно быть что-то, эквивалентное эмбриональному развитию, и что-то, эквивалентное способным к мутированию генам. Существует немало способов сделать так, чтобы компьютерная модель удовлетворяла этим требованиям. Я выбрал один из них и написал соответствующую программу. А теперь я расскажу про эту компьютерную модель, так как считаю ее очень показательной. Если вы ничего не знаете о компьютерах, просто запомните, что это такие машины, которые делают в точности то, что им говоришь, а результат нередко оказывается неожиданным. Перечень инструкций, отдаваемых компьютеру, называется программой (я пишу program, как это принято в Америке и как рекомендует Оксфордский словарь; альтернативное написание programme, распространенное в Британии, кажется мне офранцуженным и неестественным).
Развитие эмбриона — процесс слишком замысловатый, чтобы можно было реалистично сымитировать его на маленьком компьютере. Поэтому нужно придумать некий упрощенный аналог: найти такое простое правило вычерчивания рисунков, которому компьютер мог бы легко подчиняться и которое могло бы варьировать под влиянием “генов”. Какое же правило мы выберем? В учебниках по информатике часто демонстрируются возможности так называемого рекурсивного программирования на примере простого алгоритма роста деревьев. Компьютер начинает с того, что чертит одиночную вертикальную линию. Затем эта линия разветвляется на две. Затем каждая из получившихся ветвей разделяется на две ветви второго порядка. Затем каждая из этих новых ветвей разделяется на ветви третьего порядка и т. д. Такое программирование называется рекурсивным, потому что в каждой точке всего растущего дерева применяется одно и то же правило (в данном случае правило ветвления). Каким бы большим дерево ни вырастало, каждая его веточка разделяется снова и снова в соответствии все с тем же правилом.
“Глубиной” рекурсии называется такое число веточек n-го порядка, которому позволяется вырасти, прежде чем процесс будет остановлен. На рисунке 2 показано, что будет, если задать компьютеру один и тот же алгоритм черчения, но с разными значениями глубины рекурсии. При высоких степенях рекурсии получается довольно запутанный узор, однако, как ясно видно из рис. 2, достигается он за счет того же самого простейшего правила ветвления. Несомненно, это именно то, что происходит и у настоящих деревьев. Система ветвей дуба или яблони выглядит сложной, но в действительности таковой не является. Правило, лежащее в основе процесса ветвления, элементарно. Просто оно снова и снова применяется в каждой растущей верхушке каждой веточки: ветви дают начало ветвям второго порядка, каждая из которых, в свою очередь, ветвям третьего порядка и так далее. Вот почему все дерево становится в итоге большим и ветвистым.
Рекурсивная бифуркация является также хорошей метафорой эмбрионального развития как растений, так и животных. Я не хочу сказать, будто зародыши животных похожи на ветвящиеся деревья. Они на них не похожи. Но любой эмбрион растет благодаря делению клеток. Каждая клетка всегда делится на две дочерние. А гены в конечном счете всегда осуществляют свои воздействия на организм посредством локального влияния на клетки, которые раздваиваются и раздваиваются. Гены животного ни в коем случае не являются грандиозным чертежом, подробным планом строения целого организма. Как мы дальше увидим, они похожи скорее на рецепт, нежели на чертеж, и более того, на рецепт, которому следует не весь развивающийся зародыш, а каждая клетка или каждое небольшое скопление делящихся клеток. Я не отрицаю того, что любой эмбрион, а впоследствии и взрослая особь имеет некое целостное строение. Но возникает это крупномасштабное строение за счет множества мелких локальных воздействий на клеточном уровне, происходящих повсюду в развивающемся организме. И в первую очередь местные воздействия сказываются на удвоении клеток — то есть на некоей разновидности ветвления. Именно регулируя такие локальные события, гены в конечном итоге влияют и на строение взрослого организма.
Итак, простое правило ветвления выглядит как многообещающий аналог эмбрионального развития. Что ж, превращаем это правило в небольшой компьютерный алгоритм, которому даем название РАЗВИТИЕ, чтобы затем внедрить его в более масштабную программу ЭВОЛЮЦИЯ[2]. При работе над этой большой программой прежде всего следует задуматься о генах.
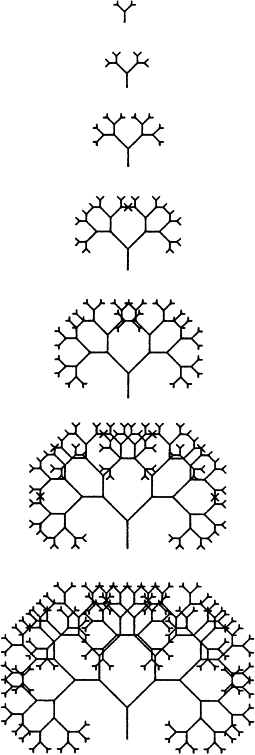
Рис. 2
Какого рода “гены” могут быть представлены в нашей компьютерной модели? В реальной жизни гены делают две вещи: влияют на индивидуальное развитие и передаются следующим поколениям. У настоящих животных и растений десятки тысяч разных генов, но мы в своей компьютерной имитации скромно ограничимся девятью. Каждый ген из этой девятки будет охарактеризован в компьютере просто неким числом, которое будет называться значением гена. Какой-то отдельно взятый ген может, к примеру, иметь значение 4 или –7.
Как же эти гены будут влиять на развитие? Ну, они могут делать это множеством разных способов. Главное, чтобы они вносили в алгоритм РАЗВИТИЕ какие-то небольшие изменения количественного характера. Например, один ген мог бы влиять на угол ветвления, а другой — на длину какой-нибудь из веточек. Еще одна возможная задача для генов, которая сразу же приходит в голову, — менять глубину рекурсии, число последовательных ветвлений. Ответственным за этот эффект я назначил ген номер 9. Таким образом, вы можете рассматривать рис. 2 как изображение семи близкородственных организмов, идентичных друг другу во всем, за исключением гена 9. Не буду вдаваться в подробности того, что именно делает каждый из восьми других генов. Представление о том, какого рода воздействия они производят, вы можете получить, изучив рис. 3. В центре расположено исходное дерево — одно из тех, что изображены на рис. 2. Вокруг него располагается еще восемь. Они точно такие же, как и то, которое в центре, но только у каждого из них был изменен — “мутировал” — какой-то из этих восьми генов. Например, картинка справа от центрального дерева показывает нам, что происходит, когда ген 5 мутирует и к его значению прибавляется 1. Будь на странице больше места, я бы расположил вокруг центрального дерева кольцо из 18 мутантов. Почему именно из 18? Потому что у нас есть девять генов, и каждый из них может мутировать в сторону как “повышения” (когда к его значению прибавляется 1), так и “понижения” (когда из его значения вычитается 1). Следовательно, 18 изображений хватило бы для того, чтобы показать всех мутантов, каких можно получить из одного центрального дерева путем единичного преобразования.
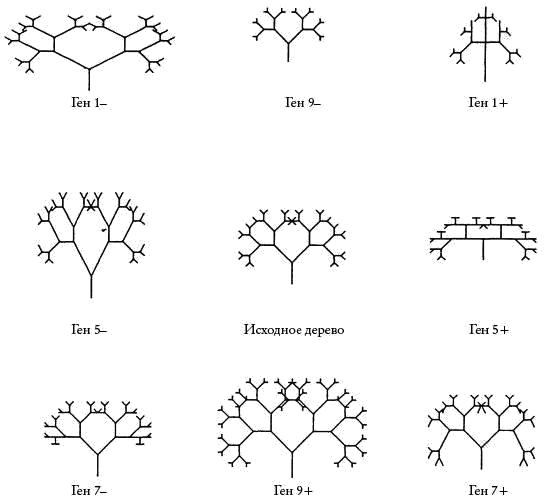
Рис. 3
У каждого из этих деревьев имеется своя собственная, уникальная “генетическая формула” — численные значения всех девяти генов. Я не стал выписывать эти генетические формулы здесь, так как сами по себе они ничего вам не скажут. Это же, кстати, справедливо и для настоящих генов. Гены начинают значить что-либо, только когда в ходе белкового синтеза преобразуются в предписания для развивающегося зародыша. То же и в нашей компьютерной модели: численные значения девяти генов обретают смысл, только будучи переведенными в указания по росту древовидного узора.
Но о работе каждого конкретного гена можно получить представление, сравнивая два организма, о которых известно, что они различаются только в этом гене. Сравните, например, исходное дерево в центре рисунка с теми, что расположены по обе стороны от него, и вы получите некоторое представление о том, что делает ген номер 5.
Ровно тем же самым занимаются и генетики в реальной жизни. Обычно генетики не знают, какими путями гены оказывают свое воздействие на эмбрионы. Не знают они и полной генетической формулы каждого животного. Но, сравнив два взрослых организма, различающиеся по одному-единственному гену, они могут увидеть, какое именно действие этот ген оказывает. На самом деле все несколько сложнее, поскольку эффекты генов взаимодействуют друг с другом способами более замысловатыми, чем простое сложение. Но то же самое верно и по отношению к компьютерным деревьям. Еще как верно, и на следующих рисунках мы это увидим.
Вы, вероятно, обратите внимание, что все формы, которые у нас получатся, будут двусторонне-симметричными. Это я установил такое ограничение для подпрограммы РАЗВИТИЕ — отчасти из эстетических соображений, отчасти чтобы уменьшить число необходимых генов (если бы гены не производили одно и то же зеркально отраженное действие на обе стороны вычерчиваемого дерева, нам понадобился бы отдельный набор генов для левой половины и отдельный — для правой), и еще отчасти потому, что надеялся получить картинки, напоминающие животных, а животные в большинстве своем довольно-таки симметричны. По этой же причине отныне я прекращаю называть эти создания “деревьями”, а буду говорить “организмы” или “биоморфы”. Название “биоморфа” придумал Десмонд Моррис — для существ, отдаленно напоминающих животных, с его сюрреалистических полотен. К его картинам я испытываю особенную привязанность, поскольку одна из них была воспроизведена на обложке моей первой книги. Моррис утверждает, что биоморфы “эволюционируют” в его воображении и что их эволюцию можно проследить по его картинам.
Но вернемся к нашим компьютерным биоморфам и к кругу из 18 возможных мутантов, восемь типичных представителей которых изображены на рис. 3. Поскольку каждый из них находится в одном-единственном мутационном шаге от исходной биоморфы, нам будет нетрудно рассматривать их всех как ее детей. Итак, у нас есть своего рода РАЗМНОЖЕНИЕ, которое, точно так же как и РАЗВИТИЕ, будет воплощено в простом компьютерном алгоритме — еще одном готовом “строительном блоке” для нашей большой программы ЭВОЛЮЦИЯ. Про РАЗМНОЖЕНИЕ следует сказать две вещи. Во-первых, никакого секса: размножение бесполое. Поэтому я полагаю, что биоморфы женского пола — ведь животные, размножающиеся без полового процесса (тли, например), почти всегда устроены как самки. Во-вторых, имеется ограничение для мутаций: всегда происходит только одна за раз. Выходит, что дочь отличается от своей родительницы только по одному из девяти генов. Более того, при каждой мутации к значению соответствующего родительского гена может быть добавлено только +1 или –1. Это не более чем произвольные условия, которые могли бы быть и иными без ущерба для биологического правдоподобия.
Нельзя сказать того же о другом свойстве нашей модели, отражающем один из основных принципов биологии. Форма потомка не создается непосредственно из родительской формы. Очертания каждой новой биоморфы определяются значениями ее собственных девяти генов (влияющих на величину углов, протяженность линий и т. п.), и каждый потомок получает свои девять генов от родительской девятки. В реальной жизни происходит ровно то же самое. Следующему поколению передается не тело — передаются гены, и только они. Гены влияют на эмбриональное развитие того тела, в котором находятся. Затем эти же гены либо передаются следующему поколению, либо нет. Участие в индивидуальном развитии организма никак не влияет на природу генов, однако вероятность их дальнейшей передачи может зависеть от успеха того тела, которое они помогали строить. Вот почему необходимо, чтобы в нашей компьютерной модели два этих процесса — РАЗВИТИЕ и РАЗМНОЖЕНИЕ — были отделены друг от друга, как два водонепроницаемых отсека. Перегородка, разделяющая их, абсолютно герметична за исключением того момента, когда РАЗМНОЖЕНИЕ передает РАЗВИТИЮ значения генов, чтобы те влияли на рост новой биоморфы. РАЗВИТИЕ ни в коем случае не передает гены РАЗМНОЖЕНИЮ обратно, иначе это был бы своего рода ламаркизм (см. главу 11).
Итак, мы составили два наших программных модуля, обозначенных как РАЗВИТИЕ и РАЗМНОЖЕНИЕ. РАЗМНОЖЕНИЕ занимается тем, что передает гены из поколения в поколение с определенной вероятностью мутации. В каждом отдельно взятом поколении РАЗВИТИЕ берет предоставленные РАЗМНОЖЕНИЕМ гены и преобразует их в действие по вычерчиванию фигурок, благодаря чему те появляются на экране компьютера. Настало время объединить эти два алгоритма в одну большую программу под названием ЭВОЛЮЦИЯ.
В сущности, ЭВОЛЮЦИЯ — это бесконечно повторяющееся РАЗМНОЖЕНИЕ. В каждом поколении РАЗМНОЖЕНИЕ получает гены от предыдущего поколения и передает их следующему — но с небольшими случайными изменениями, мутациями. Мутация состоит в том, что к значению какого-то случайно выбранного гена прибавляется +1 или –1. Из этого следует, что в ряду сменяющих друг друга поколений генетические отличия от исходного предка мало-помалу накапливаются и становятся очень большими. Но при всей случайности мутаций эти накапливаемые из поколения в поколение изменения не случайны. В любом отдельно взятом поколении биоморфы-потомки отличаются от своей родительницы случайным образом. Но в том, кто именно из этих потомков будет отобран, чтобы дать начало следующему поколению, случайности уже нет. Вот тут-то и начинает действовать дарвиновский отбор. Критерием для него служат не гены сами по себе, а организмы, на форму которых гены оказывают влияние в ходе РАЗВИТИЯ.
Помимо самовоспроизводства при РАЗМНОЖЕНИИ гены еще и передаются в каждом поколении подпрограмме РАЗВИТИЕ, которая вычерчивает на экране соответствующие организмы, следуя своим собственным строго установленным правилам. В каждом поколении нам показывается весь “выводок” “детенышей” (то есть биоморф следующего поколения). Все они являются мутантными дочерьми одного и того же родительского организма, и каждая отличается от него по какому-то одному гену. Такая невероятно высокая частота мутаций — свойство откровенно небиологическое. В действительности вероятность того, что ген мутирует, составляет зачастую меньше единицы на миллион. Причина, почему в программу был заложен такой высокий уровень мутаций, заключается в том, что все это разворачивающееся на экране компьютера действо предназначалось для человеческих глаз. Ни у какого человека не хватит терпения дожидаться одной мутации в течение миллионов поколений!
Человеческий глаз вообще сыграет в этой истории важную роль. Он будет осуществлять отбор — рассматривать всех потомков в выводке и оставлять одного на разведение. Выбранный таким образом организм даст начало следующему поколению, и теперь уже его мутантные детеныши будут все разом представлены на экране. Человеческий глаз выполняет здесь абсолютно ту же функцию, что и при выведении породистых собак или декоративных роз. Другими словами, наша модель является, строго говоря, моделью не естественного отбора, а искусственного. При настоящем естественном отборе дело обстоит так: если организм обладает качествами, нужными для выживания, то его гены выживают автоматически, поскольку находятся внутри него. То есть само собой выходит, что гены, которые выживают, это и есть те гены, которые сообщают организмам признаки, помогающие выжить. В нашей же компьютерной модели критерием отбора служит не выживание организма, а его способность отвечать человеческой прихоти. Прихоть не обязательно долж на быть праздной и случайной — ничто не мешает нам проводить селекцию по какому-то определенному признаку, такому как, например, “сходство с плакучей ивой”. Однако в моем случае человек-отборщик чаще всего был капризным и беспринципным, что не так уж отличается от некоторых разновидностей естественного отбора.
Человек указывает компьютеру, какую биоморфу из имеющегося выводка оставить для продолжения рода. Гены избранницы передаются подпрограмме РАЗМНОЖЕНИЕ, и приходит время следующему поколению появиться на свет. Подобно реальной эволюции живого этот процесс может продолжаться бесконечно. Биоморфа из любого поколения находится всего в одном мутационном шаге как от своей предшественницы, так и от наследницы. Но по прошествии 100 циклов программы ЭВОЛЮЦИЯ наши биоморфы могут оказаться где угодно в пределах 100 шагов от своего исходного предка. А 100 мутационных шагов могут далеко завести.
Однако, начиная играть с только что написанной программой ЭВОЛЮЦИЯ, я и вообразить не мог, насколько далеко. Первое, что меня удивило, — это то, как быстро мои биоморфы перестали быть похожими на деревья. Исходное раздваивание ветвей никуда не делось, но оказалось, что его можно с легкостью завуалировать многократным пересечением линий, образующим сплошные цветовые пятна (иллюстрации, увы, только черно-белые). На рисунке 4 показана одна конкретная история эволюционных преобразований, продолжавшаяся в течение всего-навсего 29 поколений. Матерью-прародительницей было крохотное существо, состоящее из одной-единственной точки. Но хотя предковый организм — всего лишь точка (как бактерия в первичном бульоне), его потенциал к ветвлению такой же, как и у дерева, расположенного в центре рис. 3. Просто ген номер 9 велел ему разветвиться ноль раз! Все создания, изображенные на рис. 4, являются потомками этой точки, но, чтобы не загромождать страницу, я не стал размещать на ней всех потомков, какие мне в действительности были предъявлены. Из каждого поколения я взял только успешную биоморфу (то есть давшую начало следующему поколению) и одну или двух из ее неудачливых сестер. Итак, на рисунке представлена преимущественно одна, магистральная линия эволюции, направляемая моими эстетическими предпочтениями. Все до единой стадии, принадлежащие к этой основной линии, там присутствуют.
Давайте посмотрим на рис. 4 и кратко пройдемся по первым нескольким поколениям “генеральной линии” эволюции. Во 2-м поколении точка превращается в букву Y. В течение следующих двух поколений Y увеличивается в размерах. Затем ее рога немного искривляются, как у хорошей рогатки. В 7-м поколении искривленность усиливается, и две “ветви” почти что соприкасаются кончиками. В поколении 8 они удлиняются и приобретают по паре маленьких отростков. В следующем, 9-м поколении эти отростки пропадают, а рукоятка рогатки становится более вытянутой. Поколение 10 напоминает цветок в разрезе: изогнутые боковые ветви, подобно лепесткам, обрамляют центральный вырост-“рыльце”. В 11-м поколении “цветок” укрупняется, и его форма становится чуть более сложной.
Нет нужды продолжать этот рассказ. На протяжении всех 29 поколений картинка говорит сама за себя. Обратите внимание, как мало каждая биоморфа отличается от своей предшественницы в ряду поколений и от своих сестер. Но раз каждая отличается от своей родительницы, то следует ожидать, что от своей бабки (и от своих внучек) она будет отличаться несколько больше, а от прабабки (и от правнучек) еще больше. Вот в чем суть накапливающей эволюции, хотя мы и разогнали ее до совершенно невероятной скорости, установив такую высокую частоту мутаций. По этой причине рис. 4 больше смахивает на родословную видов, а не особей, но принцип остается тем же.
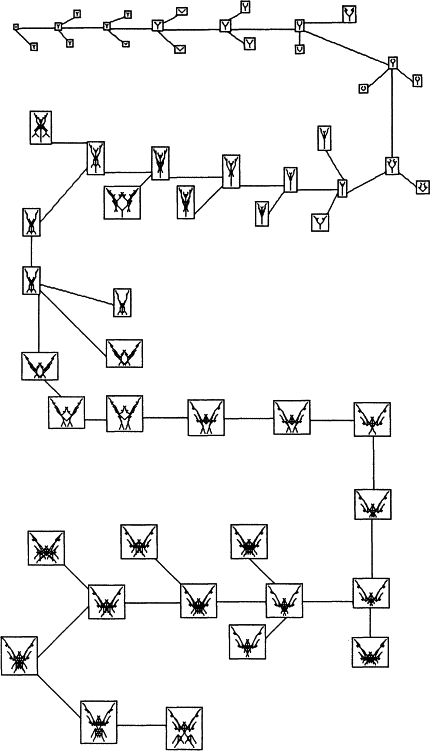
Рис. 4
Составляя программу, я никак не думал, что она сможет выдать что-нибудь кроме различных древовидных форм. Я ожидал плакучих ив, ливанских кедров, пирамидальных тополей, водорослей, в крайнем случае — оленьих рогов. Ни моя биологическая интуиция, ни мой 20-летний опыт программиста, ни самые дерзкие из моих фантазий — ничто не подготовило меня к тому, что я увидел на экране. Уже не помню, в какой именно момент меня осенило, что из получающейся последовательности может выйти нечто, напоминающее насекомое. Охваченный этой нелепой догадкой, я из поколения в поколение стал отбирать те биоморфы, которые были похожи на насекомых хоть сколько-нибудь больше других. Чем сильнее проступало сходство, тем меньше я верил своим глазам. Итоговые результаты можно увидеть в нижней части рис. 4. Правда, у них восемь ножек, как у пауков, а не шесть, как положено насекомым, — и тем не менее! До сих пор не могу удержаться и не поделиться с вами тем чувством ликования, которое я испытал, когда эти изящные существа впервые возникли передо мной на экране. В голове отчетливо зазвучали торжествующие начальные аккорды из “Так говорил Заратустра” (главный мотив в фильме “Космическая одиссея 2011 года”). От волнения я не мог есть, а ночью, когда попытался заснуть, у меня перед глазами, стоило лишь закрыть их, кишели “мои” насекомые.
Существуют и продаются компьютерные игры, в которых игроку кажется, будто он блуждает по подземному лабиринту, имеющему определенную, хотя и сложную, географию, и встречает там драконов, минотавров и прочих сказочных противников. Эти чудовища не слишком разнообразны, и все они, так же как и сам лабиринт, были разработаны человеческим разумом программиста. В эволюционной игре — как компьютерной, так и реальной — у игрока (или у наблюдателя) тоже создается впечатление, что он, образно говоря, бродит по лабиринту разветвленных коридоров, но только количество возможных маршрутов практически бесконечно, а монстры, встречающиеся на пути, непредумышленны и непредсказуемы. Когда я скитался по закоулкам Страны биоморф, мне попадались жаброногие рачки, храмы ацтеков, окна готических соборов, наскальные изображения кенгуру, а однажды — памятный, но не желающий воспроизводиться случай — вполне приемлемая карикатура на теперешнего уайкхемовского профессора логики. На рисунке 5 представлены еще некоторые трофеи из моей коллекции, все полученные одним и тем же способом. Хочу подчеркнуть: эти изображения — не плод фантазии художника. Никогда и никоим образом их не дорисовывали и не подправляли. Они именно такие, какими их вычертил компьютер, внутри которого они эволюционировали. Роль человеческого глаза сводилась только к тому, чтобы выбирать варианты из потомства, случайно мутировавшего в течение многих поколений накапливающей эволюции.
Итак, у нас появилась эволюционная модель, гораздо более близкая к действительности, чем та, которую мы могли извлечь из аналогии с обезьяной, печатающей Шекспира. Однако и эта модель несовершенна. Она наглядно демонстрирует нам, что накапливающий отбор способен давать начало почти бесконечному разнообразию квазибиологических форм, но при этом в ней используется не естественный отбор, а искусственный — осуществляемый человеком. Нельзя ли обойтись без услуг человеческого глаза, а сделать так, чтобы сам компьютер отбирал на основании какого-нибудь биологически правдоподобного критерия? Сделать это сложнее, чем может показаться на первый взгляд. Имеет смысл ненадолго остановиться и объяснить, почему.
Проводить отбор на соответствие какой-то определенной генетической формуле проще простого — при условии, конечно, что нам известны гены всех животных. Но при естественном отборе отбираются не гены сами по себе, а воздействия этих генов на организмы — то, что специалисты называют фенотипическими эффектами. У человеческого глаза хорошо получается отбирать фенотипические эффекты — это можно видеть на примере многочисленных пород собак, крупного рогатого скота, голубей, а также, если позволите, на моем рис. 5. Чтобы компьютер смог напрямую отбирать фенотипические эффекты, нам потребуется написать очень сложную программу распознавания образов. Такие программы существуют. Они применяются для чтения печатных и даже рукописных текстов. Но это область передовых, непростых для понимания технологий, где требуются очень большие и быстродействующие компьютеры. Даже если бы составление такой распознающей образы программы не выходило за пределы как моих способностей к программированию, так и возможностей моего маленького 64-килобайтного компьютера, я не стал бы с этим возиться. Эту задачу проще выполнять с помощью человеческого глаза, а если точнее, с помощью человеческого глаза, оснащенного 10-гиганейронным компьютером внутри черепной коробки.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
2. Молекулярные методы изучения изменений ДНК в ядрах
2. Молекулярные методы изучения изменений ДНК в ядрах В предыдущей главе мы уже говорили о гибридизации молекул ДНК. Этот метод позволяет сравнивать, в частности, ДНК, полученные из разных стадий развития одного вида. Если гибридизация ДНК раннего зародыша и взрослого
ГЛАВА XIV.
ГЛАВА XIV. Обработка земли под озимь.Весною 1898 г. посев начался у меня очень поздно — 21 марта по старому стилю. Была очень сухая весна, и нетрудно было предвидеть, что почва ссохнется, как кирпич, так что мелко вспахать землю под озимь будет очень трудно.Поэтому тотчас же
ГЛАВА XV.
ГЛАВА XV. Обработка земли под яровые хлеба.Обработку земли под яровые хлеба я начинаю тотчас после уборки озими . Только при соблюдении этого условия можно рассчитывать на самый обильный урожай.Поля, поросшие сорными травами и покрытые густым жнивьем, я вспахиваю
ГЛАВА XVI.
ГЛАВА XVI. Посев.Как нужно сеять, чтобы получить самый обильный урожай? Чтобы ответить на этот вопрос, нам нужно будет припомнить те условия, при которых растения развиваются в желательном для земледельца направлении. Эти условия, о которых мы говорили во второй главе,
Глава I
Глава I Восемь лет назад я написал небольшую книгу «Аксиомы биологии»[1], в конце которой высказал предположение, что возможно создание общей теории эволюции последовательно реплицирующихся систем. Завершил я книгу словами: «Под эту категорию попадают не только объекты
Общие закономерности изменений клеток при их ускоренном размножении
Общие закономерности изменений клеток при их ускоренном размножении Наиболее подробно эти закономерности изложены в монографии И. Г. Акоева и Н. Н. Мотлоха «Биофизический анализ предпатологических и предлейкозных состояний» [1984]. Ниже конспективно изложены материалы из
Глава 2. ДНК
Глава 2. ДНК На стене паба “Орел” в Кембридже висит синяя мемориальная доска, установленная в 2003 году в честь пятидесятилетия одного случая, когда разговоры в этом пабе приняли не совсем обычный оборот. Во время обеда 28 февраля 1953 года два завсегдатая “Орла”, Джеймс
ГЛАВА 5
ГЛАВА 5 С помощью Пам Смарт мне удалось разработать более простую и эффективную методику работы с людьми, испытывающими фантомные ощущения в отсутствующих конечностях, чем та, которая была описана в пятой главе.Мы провели серию опытов с людьми, у которых были
Гетерохрония - классический механизм эволюционных изменений
Гетерохрония - классический механизм эволюционных изменений Попытки найти механизмы эволюции, связанные своими корнями с онтогенезом, сосредоточены главным образом на гетерохронии - изменениях относительных сроков процессов развития. Геккель подчеркивал зависимость
Глава четвертая Энтропия Источник изменений
Глава четвертая Энтропия Источник изменений Не знающий второго начала термодинамики подобен тому, кто никогда не читал творений Шекспира.[14] Ч.П. Сноу Великая идея: изменения являются следствием бесцельного падения энергии и вещества в беспорядокЕсть вопрос, который
Новизна изменений
Новизна изменений Новизна прибавляет много напрасных страхов. Плутарх. Гай Марий, XVI Принципиальным отличием современного определения стресса от предложенного Селье служит указание на то, что для его развития необходима новизна изменений в окружающей среде. Отклонение
Глава III. Мир РНК-ДНК
Глава III. Мир РНК-ДНК 3.1. Миры до РНК и мир РНК Многие исследователи полагают, что первым клеточным миром был мир РНК (Ferris, 1999; Hoenigsberg, 2003). Однако по причинам, рассмотренным выше, более правдоподобна версия, согласно которой в ранних клетках функционировали информационные
Глава 10. Уши{10}
Глава 10. Уши{10} Того, кто заглянет поглубже в ухо, чтобы увидеть, как устроен наш орган слуха, ждет разочарование. Самые интересные структуры этого аппарата скрыты глубоко внутри черепа, за костяной стенкой. Добраться до этих структур можно только вскрыв череп, удалив мозг,
Глава 13 Внесение изменений
Глава 13 Внесение изменений В 1821 году состоялась премьера оперы композитора Карла Марии фон Вебера «Вольный стрелок». Герой оперы, Макс, хочет жениться на Агате и, дабы произвести впечатление на отца девушки, намерен победить на состязании стрелков. Отчаянно боясь
Глава 13. Внесение изменений
Глава 13. Внесение изменений …разработал первые препараты для борьбы с сифилисом, облегчив страдания миллионов. Bosch, Rosich, 2008.…возможно, на такое название его как раз и вдохновила популярная опера Вебера. Strebhardt, Ullrich, 2008.…последнее средство, когда все иные методы лечения