Рассказ Гиббона
Рассказ Гиббона
Свидание 4 является первым случаем, когда мы встречаем группу путешественников, большую, чем совокупность уже объединенных видов. Более того, могут возникнуть проблемы с установлением родственных связей. Эти проблемы усугубятся по мере продвижения в нашем странствии. Как решить их – тема «Рассказа Гиббона» (Предмет этого рассказа неизбежно делает его более трудным, чем другие части книги. Читатели должны или серьезно напрячь мысли на следующих десяти страницах, или пропустить их и вернуться к рассказу, когда они захотят поупражнять свои нейроны. Кстати, я часто задавался вопросом, какова на самом деле «интеллектуальная кепка» (Put on thinking caps— «пораскинуть мозгами», дословно «надеть интеллектуальную кепку» — прим. Пер.). Хотел бы я ее иметь. Мой благодетель Чарльз Симони (Charles Simonyi), один из самых великих компьютерных программистов в мире, как говорят, носит специальный «костюм, устраняющий ошибки», который может помочь объяснить его огромный успех.).
Мы видели, что есть 12 видов гиббонов, разделенных на четыре главных группы. Это Bunopithecus (группа, состоящая из единственного вида, обычно известного как хулок), Hylobates (шесть видов, из которых наиболее известен белорукий гиббон Hylobates lar), Symphalangus (чёрный гиббон симанг), и Nomascus (четыре вида «хохлатых» гиббонов). В этом рассказе объясняется, как построить эволюционные родственные отношения или филогенез, связав эти четыре группы.
Генеалогические деревья могут быть «корневыми» или «бескорневыми». Когда мы перемещаемся по корневому дереву, мы знаем, где находится предок. Большинство деревьев на схемах в этой книге корневые. У бескорневых деревьев, в отличие от них, нет никакого ориентированного направления. Их часто называют звездчатыми диаграммами, и у них нет никакой стрелы времени. Они не начинаются с одного края страницы и не заканчиваются на другом. Вот три примера, которые охватывают возможности родственных взаимоотношений четырех субъектов.
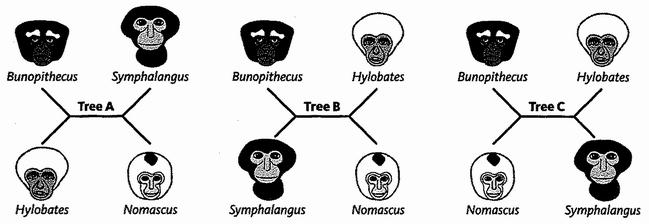
Для каждой развилки дерева не имеет никакого значения, какая из ветвей является левой, а какая правой. И пока (хотя это изменится позже в ходе рассказа) длины ветвей не несут никакой информации. Схема дерева, длины ветвей которого не имеют значения, известна как кладограмма (в данном случае бескорневая кладограмма). Порядок ветвления – единственная информация, передаваемая кладограммой: остальное только создает внешний вид. Попробуйте, например, развернуть любую из развилок в другую сторону относительно горизонтальной линии в середине. Это не будет иметь никакого значения для схемы взаимоотношений.
Эти три бескорневых кладограммы представляют единственно возможные способы соединить четыре вида, при условии, что мы ограничиваемся связями через ветви, которые только разделяются надвое (дихотомия). Как и в случае с корневыми деревьями, здесь обычно не принимается во внимание разделение на трое (трихотомия) или более (полихотомия) как временное их непризнание – «неразложимость».
Любая бескорневая кладограмма превращается в корневую в тот момент, когда мы определяем первоначальный пункт («корень») дерева. Некоторые исследователи – те, на чьи деревья мы положились в начале этого рассказа – предложили корневую кладограмму гиббонов, показанную ниже слева. Однако другие исследователи предложили корневую кладограмму справа.
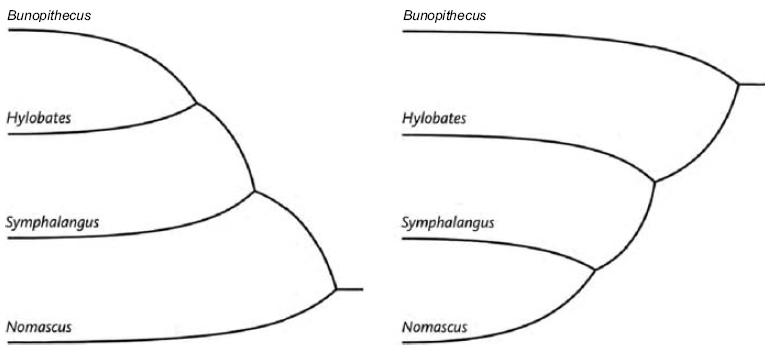
В первом дереве хохлатые гиббоны, Nomascus, являются отдаленными родственниками всех других гиббонов. Во втором – хулок, Bunopithecus, проявляет такую особенность. Несмотря на их различия, оба происходят от одного и того же бескорневого дерева (дерево A). Кладограммы отличаются только по расположению их корня. Первая образована привязкой корня дерева к ветви, ведущей к Nomascus, вторая помещает корень на ветвь, ведущую к Bunopithecus.
Как мы «укореняем» дерево? Применяя обычный метод, мы должны расширить дерево, чтобы включить, по крайней мере, одного – а лучше более чем одного – «outgroup»: члена группы, который, как заранее повсеместно установлено, был бы только отдаленно связан со всеми другими. Для дерева гиббона, например, орангутан или горилла – или, безусловно, слоны или кенгуру – могли быть использованы как outgroup. Однако сомнительно, что мы сможем выяснить родственные отношения среди гиббонов; мы знаем, что общий предок любого гиббона с большими обезьянами или слонами старше, чем общий предок любого гиббона с любым другим гиббоном: не вызывает сомнения, что корень дерева, которое включает гиббонов и больших обезьян, нужно поместить где-то между ними. Легко проверить, что три бескорневых дерева, которые я нарисовал, являются единственно возможными дихотомическими деревьями для четырех групп. Для пяти групп имеется 15 возможных деревьев. Но не пытайтесь сосчитать число возможных деревьев, скажем, для 20 групп. Оно исчисляется в сотнях миллионов миллионов миллионов. Фактическое число круто возрастает с увеличением количества систематизируемых групп, и даже самый быстрый компьютер может считать вечно. В принципе, однако, наша задача проста. Из всех возможных деревьев мы должны выбрать то, которое лучше всех объясняет общие черты и различия между нашими группами.
Как нам судить, какое «лучше всех объясняет»? Когда мы смотрим на ряд животных, перед нами предстает бесконечное разнообразие сходств и различий. Но их сложнее истолковать, чем Вам может показаться. Часто одной «особенностью» является сложная часть другой. Если Вы считаете их как отдельные, Вы в действительности считаете одно и то же дважды. В качестве чрезвычайного примера приведем четыре вида многоножек, A, B, C, и D. A и B напоминают друг друга во всех отношениях за исключением того, что у A красные ноги, а у B – синие. C и D – тоже похожи друг на друга и очень отличаются от A и B, за исключением того, что у C красные ноги, в то время как у D – синие. Если мы считаем цвет ног как единственную «особенность» мы правильно группируем AB отдельно от CD . Но если мы наивно посчитаем каждую из 100 ног как отдельную, то их цвет даст стократное увеличение числа особенностей, подтверждающих альтернативное группирование AC против BD. Все могли бы согласиться, что мы ложно посчитали одну и ту же особенность 100 раз. Это – «в действительности» всего одна особенность, потому что единственное эмбриологическое «решение» определило цвет всех 100 ног одновременно.
То же самое справедливо для двусторонней симметрии: эмбриология работает таким образом, что, за немногими исключениями, каждая сторона животного является зеркальным отображением другой. Никакой зоолог не посчитал бы каждую зеркальную особенность дважды при создании кладограммы, но их зависимость не всегда настолько очевидна. Голубь нуждается в мощной грудине для крепления летательных мышц. Бескрылой птице, такой как киви, она не нужна. Считаем ли мы мощную грудину и машущие крылья как две отдельных особенности, которыми голуби отличаются от киви? Или мы считаем их только как единственную особенность, на том основании, что строение одного признака определяет другой, или, по крайней мере, уменьшает его способность варьировать? В случае с многоножками и отражением разумный ответ довольно очевиден. В случае грудин это не так. Разумные люди могут иметь противоположные мнения.
На этом можно покончить с видимыми подобиями и различиями. Но видимые особенности развиваются только тогда, когда они являются проявлениями последовательностей ДНК. В настоящее время мы можем сравнивать последовательности ДНК непосредственно. Как дополнительное преимущество, будучи длинными последовательностями, тексты ДНК обеспечивают намного больше материала для расчета и сравнения. Проблемы комплекса крыла-и-грудины, вероятно, будут заглушены в потоке данных. Что еще лучше, многие различия в ДНК будут невидимы для естественного отбора, и таким образом обеспечен «более чистый» сигнал родословной. Как крайний пример, некоторые кодоны ДНК синонимичны: они определяют одну и ту же аминокислоту. Мутация, которая изменяет слово ДНК на один из его синонимов, невидима для естественного отбора. Но генетику такая мутация не менее видима, чем любая другая. То же самое справедливо и для «псевдогенов» (обычно случайных копий реальных генов) и для многих других последовательностей «мусорной» ДНК, которые находятся в хромосоме, но никогда не читаются и никогда не используются. Независимость от естественного отбора позволяет ДНК свободно видоизменяться путями, которые оставляют очень информативные следы для таксономистов. Ничто из этого не отменяет факт, что некоторые мутации действительно имеют реальные и важные эффекты. Даже если они являются только верхушками айсбергов, именно эти верхушки видимы для естественного отбора и отвечают за всю видимую и привычную красоту и сложность жизни.
ДНК также весьма уязвима к проблеме многократного подсчета – молекулярный эквивалент ног многоножек. Иногда последовательность дублирована многократно повсюду в геноме. Приблизительно половина человеческой ДНК состоит из многократных копий бессмысленных последовательностей, «взаимозаменяемых элементов», которые могут быть паразитами, захватившими механизмы репликации ДНК, чтобы распространиться о геноме. Только один из этих паразитных элементов, Alu, присутствует более чем в миллионе копий у большинства людей, и мы встретим его снова в «Рассказе Обезьяны-Ревуна». Даже в случае значащей и полезной ДНК есть несколько примеров, когда гены присутствуют во множестве идентичных (или почти идентичных) копий. Но на практике многократный подсчет не становится проблемой, потому что дуплицированные последовательности ДНК обычно легко опознать.
Как лучшее основание для предостережения, обширные области ДНК иногда выявляют загадочные сходства между сравнительно неродственными существами. Никто не сомневается, что птицы более близко связаны с черепахами, ящерицами, змеями и крокодилами, чем с млекопитающими (см. Свидание 16). Однако у последовательностей ДНК птиц и млекопитающих есть больше подобия, чем можно было бы ожидать, учитывая их отдаленные родственные отношения. У обоих есть избыток соединений G-C в их некодирующей ДНК. Соединение G-C химически более сильно, чем A-T, и может случиться так, что виды с теплой кровью (птицы и млекопитающие) нуждаются в более сильно связанной ДНК. Какой бы ни была причина, мы должны остерегаться позволять этому смещению G-C убедить нас в близких родственных связях между всеми животными с теплой кровью. ДНК, кажется, обещает утопию для биологических таксономистов, но мы должны знать о таких опасностях: есть многое, что мы все еще не понимаем в геномах.
Итак, произнеся необходимые предостерегающие заклинания, как мы можем использовать информационные подарки ДНК? Очаровательно, литературоведы используют те же методы, что и эволюционные биологи в рассмотрении родословных текстов. И едва ли не слишком хорошо, чтобы быть правдой – одним из лучших примеров оказалась работа над проектом «Кентерберийских рассказов». Члены этого международного синдиката литераторов использовали инструменты эволюционной биологии, чтобы проследить историю 85 различных версий рукописи «Кентерберийских рассказов». Эти древние рукописи, скопированные от руки до появления печати, являются нашей главной надеждой на восстановление потерянного оригинала Чосера. Как и в случае с ДНК, текст Чосера сохранился, пройдя через повторные копирования, со случайными изменениями, увековеченными в копиях. Придирчиво ведя подсчет накопленных различий, ученые могут восстановить историю копирования, эволюционное дерево этого воистину эволюционного процесса, состоящего из постепенного накопления ошибок в последовательных поколениях. Методы и трудности в эволюции ДНК и эволюции литературных текстов столь подобны, что каждая может использоваться для иллюстрации другой.
Итак, давайте временно обратимся от наших гиббонов к Чосеру, к четырем из 85 отдельным версиям рукописи «Кентерберийских рассказов»: «Британской Библиотеки», «Церкви Христа», «Эджертона», и версии «Хенгврт» (Манускрипт «Британской библиотеки» принадлежал Генри Дину, архиепископу Кентерберийскому в 1501 году, и вместе с манускриптом «Эджертона» и другими теперь хранится в Британской библиотеке в Лондоне. Манускрипт «Церкви Христа» теперь пребывает недалеко от того места, где я пишу, в библиотеке Церкви Христа в Оксфорде. Самое раннее упоминание о манускрипте «Хенгврта» обнаруживает его принадлежащим Флюку Даттону в 1537 году. Поврежденный крысами, грызущими овчину, на которой он написан, он находится теперь в Национальной библиотеке Уэльса.). Здесь – первые две строчки пролога:
БРИТАНСКАЯ БИБЛИОТЕКА:
Whan that Apiylle / wyth hys showres
The drowhte of Marche / hath pcede to the rote
ЦЕРКОВЬ ХРИСТА:
Whan that Auerell w’ his shoures soote
The droght f Marche hath peed to the roote
ЭДЖЕРТОН:
Whan that Aprille with his showres soote
The drowte of marche hath peed to the roote
ХЕНГВРТ:
Whan that Aueryll w’ his shoures soote
The droghte of March / hath peed to the roote
Первое, что мы должны сделать с ДНК или с литературными текстами, определить местонахождения сходств и различий. Для этого мы должны их «выровнять» – не всегда легкая задача, поскольку тексты могут быть фрагментарными или смешанными и неравной длины. Компьютер – большая помощь, когда приходится туго, но мы не нуждаемся в нем, чтобы выровнять первые две строчки пролога Чосера, в которых я выделил четырнадцать позиций, где источники расходятся.

У двух мест, второго и пятого, есть три варианта, а не два. Это составляет в общей сложности шестнадцать «значений». Собрав список различий, мы теперь решаем, какое дерево лучше всего их объясняет. Есть много способов сделать это, и все могут использоваться для животных так же, как для литературных текстов. Самый простой – сгруппировать тексты на основе полного подобия. Он обычно основывается на некоторых вариантах следующего метода. Сначала мы определяем местонахождение пары текстов, которые являются самыми подобными. Затем мы рассматриваем эту пару как единый усредненный текст, и ставим рядом с оставшимися текстами, потом мы ищем следующую самую подобную пару. И так далее, формируя последовательно вложенные группы, пока дерево отношений не будет создано. Методы такого типа – одни из самых часто используемых известны как «присоединение соседа» – быстры при вычислениях, но не включают логику эволюционного процесса. Они – просто меры подобия. Поэтому «кладистская» школа таксономии, которая очень эволюционна в своей основе (хотя не все ее участники понимают это) предпочитает другие методы, из которых ранее всех был разработан метод экономичности.
Экономичность, как мы заметили в «Рассказе Орангутана», здесь означает экономику объяснений. В эволюции животных или рукописей самое экономное объяснение то, которое постулирует наименьшее количество эволюционных изменений. Если два текста разделяют общую черту, экономное объяснение состоит в том, что они совместно унаследовали ее от общего предка, а не в том, что каждый развил ее независимо. Это далеко не неизменное правило, но оно, по крайней мере, с большей вероятностью будет оправдано, нежели его противоположность. Метод экономичности – во всяком случае, в принципе – просматривает все возможные деревья и выбирает то, которое минимизирует количество изменений.
Когда мы выбираем деревья, исходя из их экономичности, определенные типы различий не могут помочь нам. Различия, которые уникальны для единственной рукописи или единственного вида животного неинформативны. Метод присоединения соседа использует их, но метод экономичности игнорирует их полностью. Экономичность полагается на информативные изменения, которые отражены более чем в одной рукописи. Предпочтительное дерево – то, которое использует совместную родословную, чтобы объяснить столько информативных различий, сколько возможно. В наших чосеровских линиях есть пять таких информативных различий. Четыре из них разделяют рукописи на:
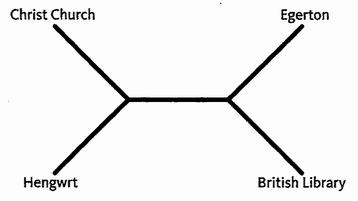
{Британская Библиотека плюс Эджертон} против {Церковь Христа плюс Хенгврт}.
Это различия, выделенные первой, третьей, седьмой и восьмой линиями. Пятое, делительная черта (косой штрих), выделенная двенадцатой линией, разделяет рукописи по-другому:
{Британская Библиотека плюс Хенгврт} против {Церковь Христа плюс Эджертон}.
Эти разделения противоречат друг другу. Мы не можем построить дерево, в котором каждое изменение случается только однажды. Лучшее дерево, которое мы можем создать, является следующим (отметьте, что это – бескорневое дерево). Оно минимизирует конфликт, требуя только, чтобы делительная черта появилась или исчезла дважды.
Фактически в этом случае у меня нет большой уверенности в нашем предположении. Конвергенции или реверсии распространены в текстах, особенно когда значение стиха не изменяется. У средневекового писца могло возникнуть небольшое раскаяние при изменении правописания, и даже меньшее при вставке или удалении знака препинания, такого как делительная черта. Лучшими индикаторами взаимоотношений были бы такие изменения, как перестановка слов. Генетические аналоги – «редкие геномные изменения»: такие события, как большие вставки, делеции или дупликации ДНК. Мы можем явно учесть их, присваивая больший или меньший вес различным типам изменений. Изменения, известные как общие или ненадежные, являются легковесными, и используются при подсчете дополнительных изменений. Изменениям, о которых известно, что они редкие или являются надежными индикаторами родства, придается надбавка в весе. Тяжелая надбавка к изменению означает, что мы вовсе не хотим посчитать ее дважды. Самое экономное дерево в этом случае то, у которого самый малый общий вес.
Метод экономичности широко используется для построения эволюционных деревьев. Но если конвергенции или реверсии распространены – как во многих последовательностях ДНК, а также в наших чосеровских текстах – экономичность может вводить в заблуждение. Это проблема, печально известная как «притяжение длинных ветвей». Вот, что она означает.
Кладограммы, корневые или бескорневые, передают только порядок перехода. Филограммы или филогенетические деревья (по-греческий phylon = раса/племя/класс), похожи на них, но используют также и длину ветвей для передачи информации. Обычно длина ветви обозначает эволюционное расстояние: длинные ветви представляют большие изменения, короткие – небольшие изменения. Первая строка «Кентерберийских рассказов» приводит к следующей филограмме:
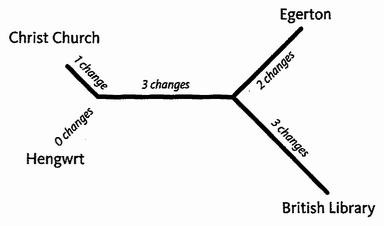
В этой филограмме ветви не слишком отличаются по длине. Но вообразите, что случилось бы, если бы какие-либо две рукописи сильно изменились по сравнению с двумя другими. Ветви, ведущие к ним, протянулись бы очень далеко. Но пропорции изменений не стали бы уникальными. Они просто стали бы идентичными с изменениями в другом месте дерева, но (и в этом все дело), особенно с изменениями на другой длинной ветви. Это справедливо потому, что большинство изменений, так или иначе, сосредоточены на длинных ветвях. Достаточное количество эволюционных изменений ложно связывает две длинных ветви и заглушает истинный сигнал. Основанная на простом подсчете числа изменений, экономичность ложно группирует концы особенно длинных ветвей. Метод экономичности заставляет длинные ветви ошибочно «притягивать» друг друга.
Проблема «притяжения длинных ветвей» – главная головная боль биологических таксономистов. Она поднимает голову всякий раз, когда распространены конвергенции и реверсии, и, к сожалению, мы не можем надеяться избежать ее, рассматривая больше текста. Наоборот, чем больше текст, который мы рассматриваем, тем больше ошибочных общих черт мы находим и сильнее укрепляется наша убежденность в неправильном ответе. Такие деревья, как говорят, лежат в угрожающе звучащей «зоне Фельзенштайна», названной в честь выдающегося американского биолога Джо Фельзенштайна. К сожалению, информация ДНК особенно уязвима к притяжению длинных ветвей. Главная причина в том, что существует только четыре буквы в коде ДНК. Если большинство различий являются изменениями единственной буквы, независимая случайная мутация в той же букве особенно вероятна. Притяжение длинных ветвей создает для нас минное поле. Ясно, что в этих случаях мы нуждаемся в альтернативе экономичности. Она сводится к форме техники, известной как анализ вероятности, которая все больше и больше помогает в биологической таксономии.
Анализ вероятности использует даже больше компьютерной производительности, чем экономичность, потому что теперь важна длина ветвей. Таким образом, мы имеем дело с намного большими деревьями, потому что, в дополнение к рассмотрению всех возможных образцов ветвления, мы должны также рассматривать все возможные длины ветвей – Гераклова задача. Это означает, что, несмотря на умные сокращенные методы, сегодняшние компьютеры могут справиться с анализом вероятности, вовлекающим лишь небольшое число видов.
«Вероятность» не является неопределенным термином. Напротив, у нее есть точное значение. Для дерева специфической формы (не забываем включать длины ветвей) из всех возможных эволюционных путей, которые могли бы создать филогенетическое дерево такой же формы, только крошечное число образует точно те же тексты, которые мы теперь видим. «Вероятность» данного дерева – исчезающе маленькая вероятность окончиться фактическими существующими текстами, а не любыми другими текстами, которые могли быть созданы таким деревом. Хотя значение вероятности для дерева является крошечной, мы все еще можем использовать сравнение одного очень маленького значения с другим как способ оценки.
В анализе вероятностей есть различные альтернативные методы получения «лучшего» дерева. Самое простое – искать одно дерево с самой высокой вероятностью: наиболее вероятное дерево. Не безосновательно такой способ имеет название «максимальная вероятность», но только то, что это – единственное наиболее вероятное дерево, не означает, что другие возможные деревья намного менее вероятны. Позже было предложено, чтобы вместо того, чтобы доверять единственному наиболее вероятному дереву, мы рассматривали все возможные деревья, но оказывали пропорционально большее доверие более вероятным. Этот подход, альтернативный максимальной вероятности, известен как филогения Байеса (Bayesian phylogeny). Если много вероятных деревьев согласуются в специфической точке ветвления, то мы считаем, что у нее есть высокая вероятность того, чтобы быть правильной. Конечно, так же, как в максимальной вероятности, мы не можем рассмотреть все возможные деревья, но есть способы сокращенных вычислений, и они работают вполне прилично.
Наша уверенность в дереве, которое мы, наконец, выбираем, будет зависеть от нашей уверенности, что его различные ветви правильны, и мы обычно помещаем значения вероятностей около каждой точки ветвления. Вероятности вычисляем автоматически, используя метод Байеса, но для других способов, таких как экономичность или максимальная вероятность, мы нуждаемся в альтернативных мерах. Обычно используется метод «bootstrap», который неоднократно производит повторную выборку различных данных, чтобы выяснить, насколько большие отклонения создаются в окончательном дереве – другими словами, насколько дерево устойчиво к ошибке. Чем выше значение «bootstrap», тем больше заслуживает доверия точка разветвления, но даже эксперты бьются над тем, как точно истолковать, что говорит нам специфическая величина «bootstrap». Подобные методы – «складной нож» и «индекс распада». Все они – меры того, насколько мы должны доверять каждой точке ветвления дерева.
Прежде, чем мы оставим литературу и возвратимся к биологии, вот итоговая диаграмма эволюционных отношений между первыми 250 строчками 24 рукописей Чосера. Это филограмма, в которой не только схема ветвления, но и длины линий имеют значение. Вы можете непосредственно прочитать, какие рукописи незначительно отличаются друг от друга, а какие сильно отклонились. Филограмма бескорневая – в ней не зафиксировано, какая из этих 24 рукописей наиболее близка к «оригиналу».
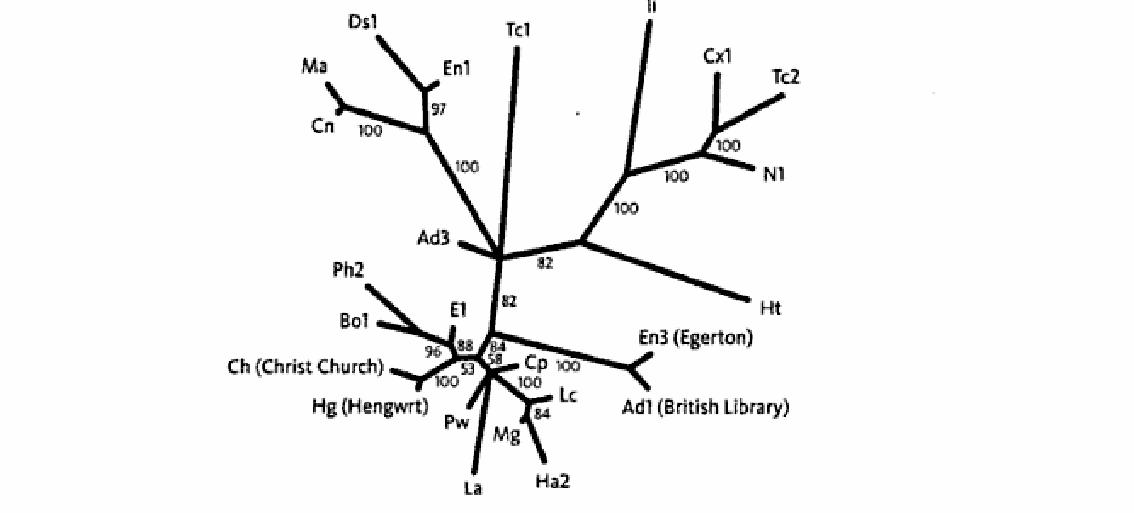
Пришло время возвращаться к нашим гиббонам. За эти годы многие люди пытались выяснить наши родственные отношения с гиббонами. Экономичность предсказала четыре группы гиббонов. На следующей странице – корневая кладограмма, основанная на физических особенностях.
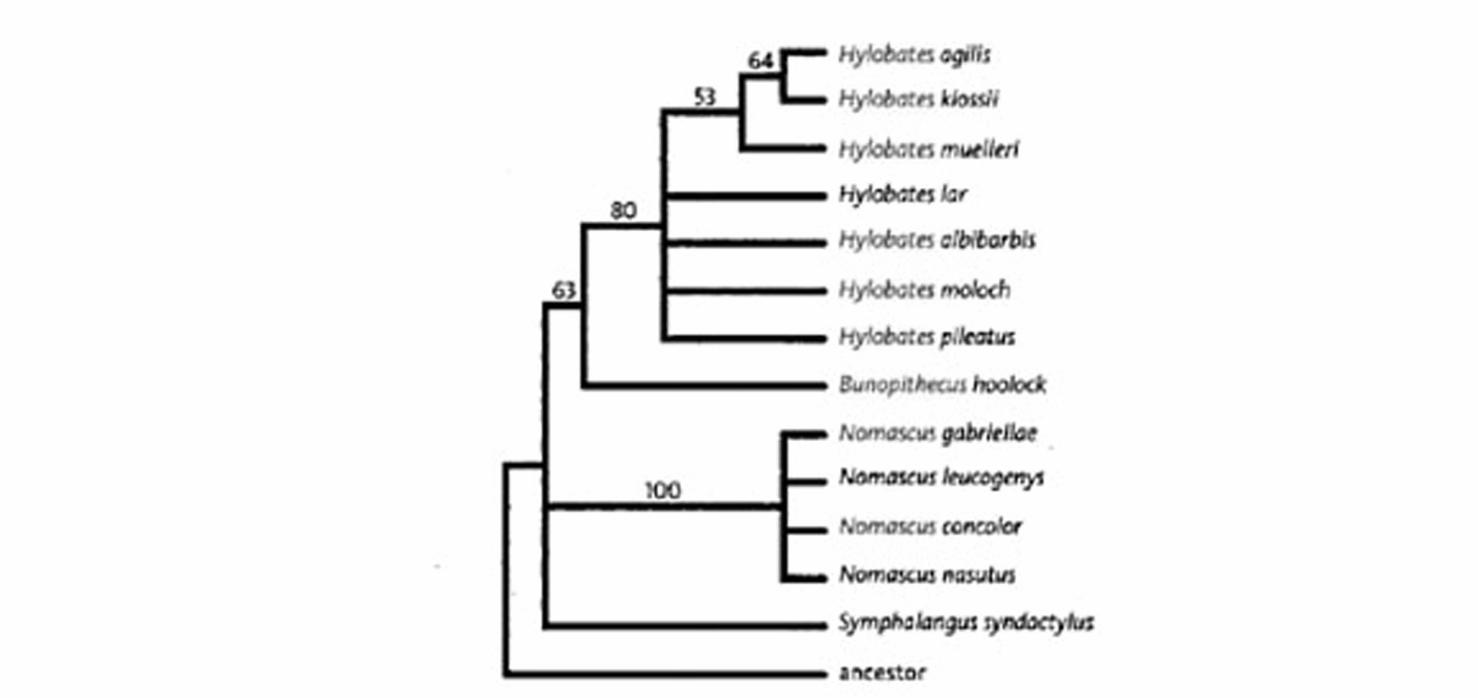
Эта кладограмма убедительно показывает, что виды Hylobates образуют группу, также как Nomascus. У обеих групп относительно высокие значения bootstrap (числа на линиях). Но в нескольких местах не решен порядок перехода. Даже притом, что выглядит, как будто бы Hylobates и Bunopithecus формируют группу, значение bootstrap 63 неубедительно для тех, кто обучен читать подобные руны. Морфологических особенностей недостаточно, чтобы построить дерево.
Поэтому Кристиан Рос и Томас Гайсман (Christian Roos, Thomas Geissmann) из Германии обратились к молекулярной генетике, а именно к участку митохондриальной ДНК, названному «областью контроля». Используя ДНК шести гиббонов, они расшифровали последовательности, выровняли их буква к букве и выполнили для них исследования на присоединение соседа, экономичность и максимальную вероятность. Максимальная вероятность, лучший из этих трех методов при преодолении притяжения длинных ветвей, дал самый убедительный результат. Его заключительный вердикт относительно гиббонов показан выше, и Вы можете увидеть, что он разрешает вопрос отношений между этими четырьмя группами. Величины bootstrap были достаточно, чтобы убедить меня использовать полученное дерево для филогении в начале этой главы.
Гиббоны разделились на отдельные виды относительно недавно. Но поскольку мы рассматриваем все более отдаленно связанные виды, разделенные все более длинными ветвями, даже сложные методы максимальной вероятности и анализа Байеса начинают нас подводить. Может создаться ситуация, когда недопустимо большая пропорция общих черт окажется случайной. Различия, как говорят в таких случаях, насыщают ДНК. Никакие причудливые методы не могут восстановить информацию о родословной, потому что любые остатки родственных отношений были уничтожены разрушительным действием времени. Проблема становится особенно острой для нейтральных различий в ДНК. Сильный естественный отбор держит гены в точном, ограниченном диапазоне. В крайних случаях важные функциональные гены могут оставаться без преувеличения идентичными в течение сотен миллионов лет. Но, для псевдогена, который никогда ничего не делает, таких отрезков времени достаточно, чтобы привести к безнадежной насыщенности. В таких случаях нам нужны другие данные. Самая многообещающая идея состоит в том, чтобы использовать редкие геномные изменения, которые я упоминал прежде – изменения, которые вовлекают перестройку ДНК, а не только замену единственной буквы. Эти редкие, безусловно, обычно уникальные, совпадающие подобия создают намного меньше проблем. И однажды найденные, они могут замечательно выявлять родственные связи, как мы выясним, когда к нашей увеличивающейся группе странников присоединится гиппопотам, и мы будем шокированы его удивительным рассказом о ките.
А теперь, важная запоздалая мысль об эволюционных деревьях, которую мы извлекли из уроков в «Рассказе Евы» и «Рассказе Неандертальца». Мы могли бы назвать ее концом гиббонов и гибелью видового дерева. Мы обычно предполагаем, что можем нарисовать единое эволюционное дерево для нескольких видов. Но «Рассказ Евы» уверил нас, что у различных частей ДНК (и таким образом различных частей организма) могут быть различные деревья. Я думаю, что это формулирует характерную проблему самой идеи видовых деревьев. Виды – смеси ДНК из многих различных источников. Как мы заметили в «Рассказе Евы» и повторили в «Рассказе Неандертальца», каждый ген, фактически каждая буква ДНК идет своим собственным путем сквозь историю. У каждой части ДНК и каждого свойства организма могут быть различные эволюционные деревья.
Примеры этого возникают ежедневно, но хорошая осведомленность принуждают нас игнорировать смысл этой информации. У марсианского таксономиста, обнаружившего гениталии только у мужчины, женщины и самца гиббона не было бы никакого сомнения в классификации этих двух мужчин как более близко сродненных друг с другом, чем с любой женщиной. Действительно, ген, определяющий мужской пол (названный SRY), никогда не был в женском теле, по крайней мере, с тех пор, как мы и гиббоны отделились друг от друга. Традиционно морфологи признают особый случай для половых признаков, избегая «бессмысленных» классификаций. Но идентичные проблемы возникают и в других местах. Мы видели это раньше с группами крови АВО в «Рассказе Евы». Мой ген группы крови В более близко связывает меня с шимпанзе группы В, чем с человеком группы А. И это относится не только к половым генам или генам группы крови, но и ко всем генам и особенностям, которые подвержены такому воздействию при определенных обстоятельствах. Большинство молекулярных и морфологических особенностей указывают, что шимпанзе – наши самые близкие родственники. Но большое меньшинство свидетельствует, что это гориллы, или, что шимпанзе наиболее близко связаны с гориллами, и они оба одинаково близки к людям.
Это не должно нас удивлять. Различные гены наследуются, проходя различными маршрутами. Популяция, предковая ко всем трем видам, будет разнородна – каждый ген имеет множество различных линий. Ген у людей и горилл, вполне возможно, имеет одну родословную, в то время как шимпанзе он был передан от более отдаленного родственника. Все, что необходимо для ранее разошедшихся линий гена, пройти через раскол человек-шимпанзе, таким образом, у людей этот ген может происходить от одной из них, а у шимпанзе от другой (Чем больше времени прошло между расколами видов (или чем меньший размер популяции), тем больший ущерб потерпели предковые линии от генетического дрейфа. Те аккуратные таксономисты, кто надеется, что деревья видов совпадут с деревьями генов, обнаружат, что легче иметь дело с животными, расколы которых достаточно растянуты во времени, в отличие от африканских обезьян. Но всегда есть гены, такие как SRY, для которого отдельные линии систематически поддерживаются естественным отбором на огромных промежутках времени.).
Таким образом, мы должны признать, что единственное дерево – не вся история. Деревья видов могут быть построены, но их нужно считать упрощенным обобщением множества генных деревьев. Я могу предложить интерпретировать дерево вида двумя различными способами. Первый – обычная генеалогическая интерпретация. Один вид – самый близкий родственник другого, если из всех видов, которые мы рассматриваем, он разделяет последнего общего генеалогического предка. Второй, я подозреваю, способ будущего. Дерево вида может быть представлено как изображение отношений среди демократического большинства генома. Оно соответствует результату «решения большинством голосов» среди генных деревьев.
Демократическая идея – генное голосование – является той, которую я предпочитаю. В этой книге все отношения между видами должны интерпретироваться таким образом. Все филогенетические деревья, которые я представляю, должны быть рассмотрены в духе генетической демократии, от отношений между обезьянами до отношений между животными, растениями, грибами и бактериями.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Рассказ Евы
Рассказ Евы Есть впечатляющая разница между «родословными деревьями генов» и «родословными деревьями людей». В отличие от человека, который происходит от двух родителей, у гена есть только один родитель. Каждый из Ваших генов должен был быть получен или от Вашей матери,
Рассказ Секвойи
Рассказ Секвойи Люди спорят о том, какое одно место в мире Вы должны посетить прежде, чем умрете. Мой кандидат – лес Muir Woods, несколько севернее моста «Золотые Ворота». Или, если Вы считаете, что слишком поздно, я не могу вообразить лучшего места, чтобы быть похороненным (вот
Рассказ Taq
Рассказ Taq Достигнув нашего самого древнего свидания, собрав в нашем странствии всю жизнь, которую знаем, мы имеем возможность рассмотреть ее разнообразие. На самом глубинном уровне разнообразие жизни является химическим. Профессии, которыми заняты наши
Рассказ Stw 573
Рассказ Stw 573 Не думаю, что есть смысл придумывать причины, в силу которых ходить на двух ногах – это здорово. Будь так, шимпанзе делали бы то же самое, не говоря уже о других животных. Нет причины, по которой бег на двух или четырех конечностях быстрее или удобнее.
Рассказ Гориллы
Рассказ Гориллы Становление дарвинизма, которое пришлось на XIX век, привело к появлению двух противоположных взглядов на человекообразных обезьян. Противники Дарвина, хотя и согласившиеся принять идею эволюции, были в ужасе от возможного родства с грубыми,
Рассказ Орангутана
Рассказ Орангутана Возможно, заявление о наших давних связях с Африкой было поспешным. Что если наши предки покинули Африку около 20 млн лет назад и поселились в Азии, а 10 млн лет назад вернулись в Африку?Если так, то современные человекообразные обезьяны, включая тех,
Рассказ Гиббона[12]
Рассказ Гиббона[12] На рандеву № 4 мы встречаем крупную группу пилигримов. И теперь могут возникнуть проблемы с установлением родства. (Чем дальше, тем затруднительнее это сделать.) Существует двенадцать видов гиббонов, принадлежащих к четырем основным группам. Это Bunopithecus
Рассказ Айе-айе
Рассказ Айе-айе Один британский политик как-то описал конкурента (который позднее стал лидером партии) как человека, “в котором есть что-то ночное”. При взгляде на айе-айе складывается именно такое впечатление, и это не случайно: она ведет целиком ночной образ жизни. Из
Рассказ Шерстокрыла
Рассказ Шерстокрыла Шерстокрыл из Юго-Восточной Азии мог бы рассказать нам, каково это – парить во воздуху ночного леса. Но для нас, пилигримов, у него приготовлена гораздо более приземленная история. Мораль ее в том, что составленная нами схема с сопредками, рандеву и
Рассказ Мыши
Рассказ Мыши Из тысяч грызунов домашняя мышь (Mus musculus) может поведать кое-что особенное: ни один другой вид млекопитающих, кроме нашего собственного, мы не изучали так интенсивно. Именно на мышах, а не на пресловутых морских свинках держатся медицинские, физиологические и
Рассказ Бобра
Рассказ Бобра “Фенотип” – это то, что находится под влиянием генов. В целом под фенотипом понимают все, что относится к телу. Но есть тонкости, вытекающие из этимологии. Phamo по-гречески означает “показывать”, “обнаруживать”, “выявлять”, “выражать”, “раскрывать”.
Рассказ Гиппопотама
Рассказ Гиппопотама В школе, изучая греческий, я узнал, что “гиппос” означает “лошадь”, а “потамос” – “река”. Выходило, что гиппопотамы – “речные лошади”. Позднее, забросив греческий и занявшись зоологией, я узнал, что гиппопотамы не имеют отношения к лошадям. В
Рассказ Тюленя
Рассказ Тюленя В большинстве естественных популяций число самцов и самок примерно одинаково. На то есть эволюционные причины, и о них рассказал замечательный специалист по статистике и эволюционной генетике Рональд Э. Фишер. Представьте себе популяцию, количество в
Рассказ Броненосца
Рассказ Броненосца С зоологической точки зрения Южная Америка сродни Мадагаскару: как и Мадагаскар, она откололась от Африки – но не с восточной, а с западной стороны. Произошло это примерно тогда же или чуть позднее. Как и Мадагаскар, в течение почти всего времени
Рассказ Утконоса
Рассказ Утконоса Старое латинское название утконоса – Ornithorhynchus paradoxus [“парадоксальный птицеклюв”]. Когда его обнаружили, он показался ученым настолько нелепым, что присланный в музей экземпляр сочли чучелом из сшитых вместе частей тела млекопитающего и птицы. Кое-кто
Рассказ Taq
Рассказ Taq Итак, мы встретили практически все существующие формы жизни. Теперь можно окинуть взглядом открывшееся разнообразие. На самом глубоком уровне разнообразие жизни является химическим. Профессии, которыми владеют наши пилигримы, охватывают широкий диапазон