Глава А. Аналоговые таблицы генетического кода (XIII)
Глава А. Аналоговые таблицы генетического кода (XIII)
Первым, кто попытался упорядочить таблицу генетического кода и построить ее на рациональной основе, был наш выдающийся ученый Юрий Борисович Румер. Он был физиком, учеником Макса Борна, хорошо знал Альберта Эйнштейна, Пауля Эренфеста, Эрвина Шредингера, был другом Льва Ландау. Читал лекции в Московском университете, работал в ФИАНе. Само собой, очередная российская власть (большую часть ХХ века — советская) привычно обошлась с крупным ученым, сунув его в 1938г в лагерь, а потом в авиационную шарашку, где он работал с Туполевым, Королевым, Мясищевым, Петляковым, Глушко, Бартини, Карлом Сциллардом, братом упоминавшегося выше Лео; каждый незауряден. Ольга и Сергей Бузиновские[55] показывают целую вереницу выдающихся людей, которая незримо тянется за именем Румера — от Понтекорво до Ферми и Александра Грина, от Флерова до Сент-Экзюпери и Алексея Толстого, от Бартини до Ильфа и Петрова...
...В 1953г Румер был реабилитирован, потом работал в Академгородке под Новосибирском. Как только Ниренберг с соавторами опубликовали в 1965г полный словарь генетического кода, Румер немедленно погрузился в эту тематику. В том же году он писал: «Рассмотрение группы кодонов, относящихся к одной и той же аминокислоте, показывает, что в каждом кодоне (XYZ) целесообразно отделить двухбуквенный корень /XY/ от окончания /Z/. Тогда каждой аминокислоте, в общем случае, будет соответствовать один определенный корень, а вырожденность кода является следствием изменения окончания». Шестнадцать возможных корней он разбил на два октета (с заменой тимина Т на урацил U для РНК):

Идея о разбиении корней кодонов на два октета — «сильные» и «слабые» была совершенно новой и неожиданной для специалистов, работавших в этой области. Оказалось, что анализ многих свойств аминокислот четко подтверждает разбиение всех аминокислот на две группы, соответствующие разбиению корней на два октета. Исследованию разнообразных следствий этой идеи были посвящены несколько работ Румера. В частности, подход Румера к проблеме с однозначностью приводил к следующему порядку букв:
C — очень сильная
G — сильная
U — слабая
A — очень слабая
Заканчивая главу, упомянем еще об одной нашей находке, имеющей отношение к кодовым симметриям. Оказывается, продукты кодирования зеркально-симметричными дублетами (типа ABN и BAN) следуют трем простым правилам:
? при нарастании массы оснований в дублете кодируемый продукт имеет большую молекулярную массу, при снижении — меньшую;
? молекулярная масса продукта, кодируемого гомотриплетом (то есть, ССС, ТТТ, ААА, GGG), больше, если триплет составлен из пиримидинов;
? молекулярная масса пары аминокислот, кодируемых гомодублетом (то есть, СС-, ТТ-, АА-, GG-), больше, если он состоит из пиримидинов.
Возникает вопрос, какой смысл — и есть ли он — в кодовых симметриях и соотношениях, описанных в этой главе? Если хиральность биологических молекул и клеточная организация имеют очевидные достоинства и являются необходимыми для возникновения жизни и последующей эволюции, то симметрия (в первую очередь, билатеральная) генетического кодирования, по меньшей мере, озадачивает. Является ли она следствием каких-то не открытых еще физических или информационных законов (например исходных альтернатив, выбор которых имел селективные преимущества, похоронившие первые версии кода, значительно более разнообразные и не столь регулярные? Имеет ли она отношение к надмолекулярным симметриям биологических форм? Нужна ли подобная симметрия кода для его невероятной стабильности или для максимальной простоты и надежности его функционирования в биологических системах? Положительные ответы на все эти вопросы весьма соблазнительны, но без весьма основательной проработки — остаются лишь гипотезами, доказательства которых сегодня даже не просматриваются. Альтернативная точка зрения (Френсис Крик) заключается в том, что все эти симметрии совершенно случайны, и генетический код мог быть каким угодно: химического соответствия между аминокислотами и антикодонами нет. И если сегодня — в большинстве случаев — нельзя рассчитывать на то, что после замены антикодона на другой в синтезируемый полипептид войдет аминокислота, соответствующая новому антикодону, то это потому только, что длительная эволюция — опять-таки во многих случаях — оптимизировала соответствие АРСаз и тРНК за счет участков, выходящих за пределы антикодона.
Следующая глава написана для тех читателей, кого обе точки зрения оставляют в состоянии умственного дискомфорта. Но только те из них, кто разделяет черный оптимизм Автора, кто понимает, что если не веришь в Бога, то это не означает автоматическую «веру в Большой Взрыв», и кто не ждет от науки разрешения ассонанса в консонанс (не органчик же!), — только они получат удовольствие от того, что ответы на эти вопросы вызывают новые, еще более острые.
.....................
Сразу ясно, что символом «А» эта глава названа просто потому, что речь в ней идет об аналоговых представлениях генетического кода. Здесь мы, наконец, оставляем без внимания множество «интересных» чисел, которыми до сих пор докучали терпеливому Читателю, но к которым всё же ненадолго вернемся в последующих двух главах, посвященных оцифровке приведенных выше аналоговых представлений.
Этот порядок букв (CGUA) дает возможность сформулировать простые правила, определяющие "силу«корня:
? сила корня, содержащего вкачествевторой буквы С или А, определяется силой второй буквы;
? сила корня, содержащего в качестве второй буквы G или U, определяется силой первой буквы.
Крик предпочитал другой порядок букв в генетическом алфавите. В письме Румеру он доказывал преимущества порядка UCAG (этот порядок и сейчас используется во всех учебниках), но алфавит Румера позволял, в частности, видеть поразительные симметрии внутри генетического кода. Не вдаваясь в описание румеровской аргументации, мы предлагаем здесь свой порядок: CUAG, основанный не на качественном понятии «сила кодирующего основания», но на простом упорядочивании по нарастанию весьма простого же параметра — молекулярной массы азотистых оснований — и показываем группу наглядных симметрий, что — как и сам принцип такого упорядочивания — представляется нам даже более интересным. Но об этом позже. Что же до Юрия Борисовича Румера, то это фигура чрезвычайно интересная; о нём очень много можно прочесть в Интеренете:
...Чутьё у Румера было поразительным. То, что увлекало его в молекулярной биологии [много] лет назад, сейчас является передним краем исследований. В последние годы наблюдается явный рост числа публикаций, в которых проблемы генетического кода анализируются с привлечением симметрий и методов теории групп. Предлагаются разные подходы, основанные на разных типах групп, включая квантовые. В основном этим занимаются физики, не слышавшие о работах Юрия Борисовича. Когда они знакомятся-таки с работами Румера, то поражаются их изяществу, глубине и тому, что идеи симметрии уже [много] лет назад играли центральную роль при подходе к проблемам генетического кода...
Любопытно, в частности, что Юрий Борисович инициировал исследования и по поиску корреляций между одномерной и трехмерной структурами белков. Их не удалось довести до конца по причине существенной неполноты экспериментальных данных, отсутствия хороших компьютеров, а в основном, по-видимому, из-за недостатка энтузиазма... у молодых участников проекта. И снова современное: Не люблю я точные науки, Точно сам не знаю, почему...
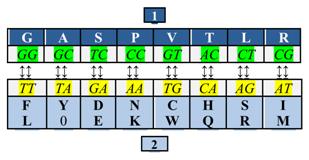
Он объединил кодоны, третья буква которых может быть любой из четырех, в один набор, а кодоны, не удовлетворяющие этому условию — в другой. Оба набора содержали равное число триплетов — по 32 каждый. При этом число кодирующих дублетов в обоих наборах составляло по восемь в каждом, поэтому наборы были названы октетами. Оба октета оказались связанными между собой простым преобразованием: T?G, C?A (ДНК-вариант):
Этот рисунок иллюстрирует румеровское преобразование, переводящее дублеты одного октета в другой. Третье основание кодона неявно присутствует здесь в составе октета II, продукты которого организованы в две строки: верхнюю кодируют триплеты с третьим пиримидином, нижнюю — с третьим пурином.
Идеи Юрия Румера были продолжены и развиты работами Владимира Щербака. Два румеровских октета Щербак преобразовал таким образом, чтобы выделить в них группы вырожденности, пронумеровав их справа налево, а продукты кодирования (аминокислоты) он упорядочил в каждой группе по нарастанию молекулярной массы слева направо; триплеты, соответствующие продуктам кодирования, он записал по вертикали сверху вниз. Тогда первые, вторые и третьи основания кодонов образовывали три строки в каждом кодоне. Вот что у него получилось (цифры под третьими основаниями — характеристики кодируемого продукта):
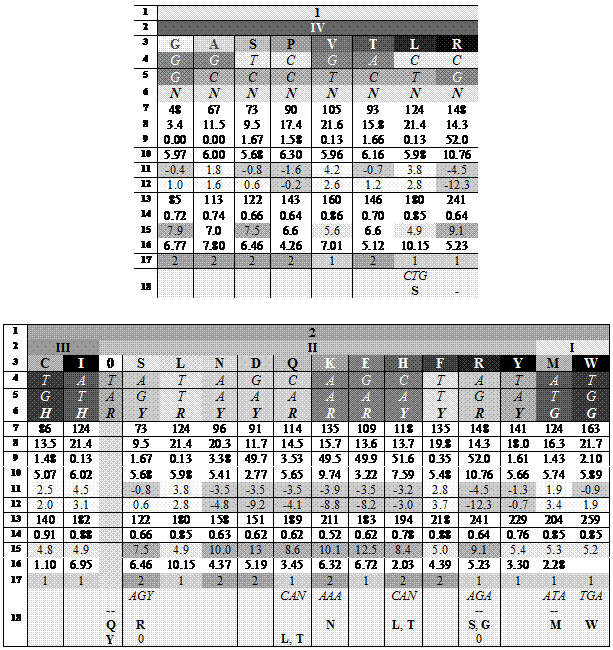
? номер октета
? номер группы вырожденности
? продукт кодирования (аминокислота или терминирующий сигнал 0)
? 1-е
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением Данный текст является ознакомительным фрагментом.
Глава XIII
Регуляция экспрессии генов
О проблеме регуляции экспрессии генов мы в этой книге говорим фактически во всех главах, рассматривая ее с разных сторон. Существует такое, может быть несколько одностороннее, определение развития: «Понять развитие — это значит
Глава XIII
ПОСЛЕДНИЕ ВЕРСТЫ ЭВОЛЮЦИИ
В прошлых главах речь шла о млекопитающих и о том, как они жили на Земле после внезапного упадка рептилий в конце мезозоя. Как одни из них «приобрели» крепкие длинные ноги, другие — когти и зубы, некоторые ушли в воду, а кое-кто, как,
ГЛАВА XIII.
Орудия для обработки земли.Бессмысленное оборачивание почвы при глубокой обработке вызвало не менее бессмысленное устройство плугов, грубберов, культиваторов, драпаков и т. п. Хотя этим орудиям, как основательно замечает Дегерен, место в музеях древностей на
Глава XIII
Открыватели кровообращения
Четыре европейца удостоены высокой чести: в ознаменование их научного подвига — открытия кровообращения — сооружены монументы:в Мадриде — в честь Мигеля Сервета;в Болонье — в честь Карло Руини;в Пизе — в честь Андреа Чезальпино;в
Глава 11. Механика генетического кодирования (XI)
Об этом можно прочитать в любом учебнике. И все же — чтобы облегчить понимание последующих рассуждений — позволим себе очень коротко остановиться на работе машины кодирования. Барбьери связывает формирование таких машин с
Глава Б. Барионная оцифровка генетического кода (XIV)
ФОРМАТЫ 1D и 2D Строго говоря, барионным числом называется сохраняемое квантовое число системы. Нам нет необходимости углубляться в эту тему. Может быть, стоит помнить лишь то, что барион — это элементарная частица,
Глава XIII
К КОМПАНИИ ПРИСОЕДИНЯЕТСЯ АДАМ
История, которую я излагаю в этой книге,— это история мира, запечатленная в гене, наиболее легко поддающемся расшифровке — митохондриальной ДНК. Можно сказать, что это весть от Евы. Изящество и простота, с которой митохондриальная
Глава XIII
Нервная система
Функции
У нервной системы живых существ имеются две основные функции. Первая — сенсорное восприятие, благодаря которому мы воспринимаем и постигаем окружающий мир. По центростремительным чувствительным нервам импульсы от всех пяти органов
Глава 11.
Механика генетического кодирования (XI)
Об этом можно прочитать в любом учебнике. И все же – чтобы облегчить понимание последующих рассуждений – позволим себе очень коротко остановиться на работе машины кодирования. Барбьери связывает формирование таких
Глава A.
Аналоговые таблицы генетического кода (XIII)
Первым, кто попытался упорядочить таблицу генетического кода и построить ее на рациональной основе, был наш выдающийся ученый Юрий Борисович Румер. Он был физиком, учеником Макса Борна, хорошо знал Альберта Эйнштейна,
Глава XIII. ПОЧЕМУ ВИАГРА СПАСЛА БОЛЬШЕ БРАКОВ, ЧЕМ ВСЕ ПСИХОТЕРАПЕВТЫ, ВМЕСТЕ ВЗЯТЫЕ?
ЯЛВ: Поговорим о событии, изменившем мир. Эта революция, в определенном смысле сексуальная революция, произошла в 1998 году. Ее по значимости можно сравнить с синтезом в пятидесятые годы
Глава 11
Взлом кода
Я сравнивал исследования, ставящие целью увидеть коннектомы, с блужданием по извилистым ходам Лабиринта. Миф гласит, что это сооружение располагалось близ дворца царя Миноса в Кноссе, на острове Крит. В 1900 году Кносс породил еще одну метафору,
Глава 11. Взлом кода
Для целого ряда мертвых языков такие попытки не привели к желаемому результату. Robinson, 2002.Он не мог назвать имя нынешнего президента… Corkin, 2002.…похоже, СВД играет важнейшую роль в накоплении новых воспоминаний, но не в хранении старых. Медики Более 800 000 книг и аудиокниг! 📚
Читайте также
Глава XIII Регуляция экспрессии генов
Глава XIII ПОСЛЕДНИЕ ВЕРСТЫ ЭВОЛЮЦИИ
ГЛАВА XIII.
Глава XIII Открыватели кровообращения
Глава 11. Механика генетического кодирования (XI)
Глава Б. Барионная оцифровка генетического кода (XIV)
Глава XIII К КОМПАНИИ ПРИСОЕДИНЯЕТСЯ АДАМ
Глава XIII Нервная система
Глава 11. Механика генетического кодирования (XI)
Глава A. Аналоговые таблицы генетического кода (XIII)
Глава XIII. ПОЧЕМУ ВИАГРА СПАСЛА БОЛЬШЕ БРАКОВ, ЧЕМ ВСЕ ПСИХОТЕРАПЕВТЫ, ВМЕСТЕ ВЗЯТЫЕ?
Глава 11 Взлом кода
Глава 11. Взлом кода